

Die Crawlbarkeit einer Ressource (Webseite, Bild, CSS-/ JS-Datei) wird durch robots.txt-Anweisungen deklariert. Um zu ermitteln, ob eine Ressource von Suchmaschinen verarbeitet werden darf, eignen sich diverse robots.txt Tester. Dadurch erfährt man, ob wichtige Seiten, Bilder und Dateien blockiert werden und Anweisungen überarbeitet werden sollten. Dieser Beitrag stellt hilfreiche robots.txt Tester vor.
Inhaltsverzeichnis
Unterschied von Crawlbarkeit und Indexierbarkeit
Zwischen Crawlbarkeit und Indexierbarkeit liegt ein wesentlicher Unterschied:
- Mit Crawlbarkeit ist gemeint, ob ein User-agent, wie Googlebot, eine Webressource verarbeiten darf. Die Regeln werden in der robots.txt-Datei notiert. Nicht crawlbare Ressourcen werden in den Suchmaschinen Ergebnissen (SERPs) nicht gefunden.
- Die Indexierbarkeit legt fest, ob eine gecrawlte Ressource von Suchmaschinen in den Suchindex aufgenommen werden darf. Grundsätzlich werden diese Anweisungen im HTML Code durch das Meta Robots Tag oder X-Robots-Tag sowie das Canonical Tag festgelegt. Nicht indexierbare Ressourcen werden in den Suchmaschinen Ergebnissen (SERPs) nicht gefunden.
robots.txt testen mit dem Screaming Frog SEO Spider
Der Screaming Frog SEO Spider ist der Branchen-Primus für Website Audits. Die Spider-Software enthält einen robots.txt Tester.
Im SEO Spider klickt man im Hauptmenü auf Konfiguration und robots.txt. Im Bereich Eigene Robots klickst Du auf den Button + Hinzufügen und gibst die Domain an (1). Nun wird der Inhalt aus der robots.txt vom Webserver gefetcht und in das Fenster (2) geladen. Durch Eingabe einer relativen URL im Feld (3) kannst Du testen, ob die absolute URL von Suchmaschinen verarbeitet werden darf. So kannst Du wichtige Seiten sowie Ressourcen prüfen, ob sie durch robots.txt-Anweisungen blockiert werden.
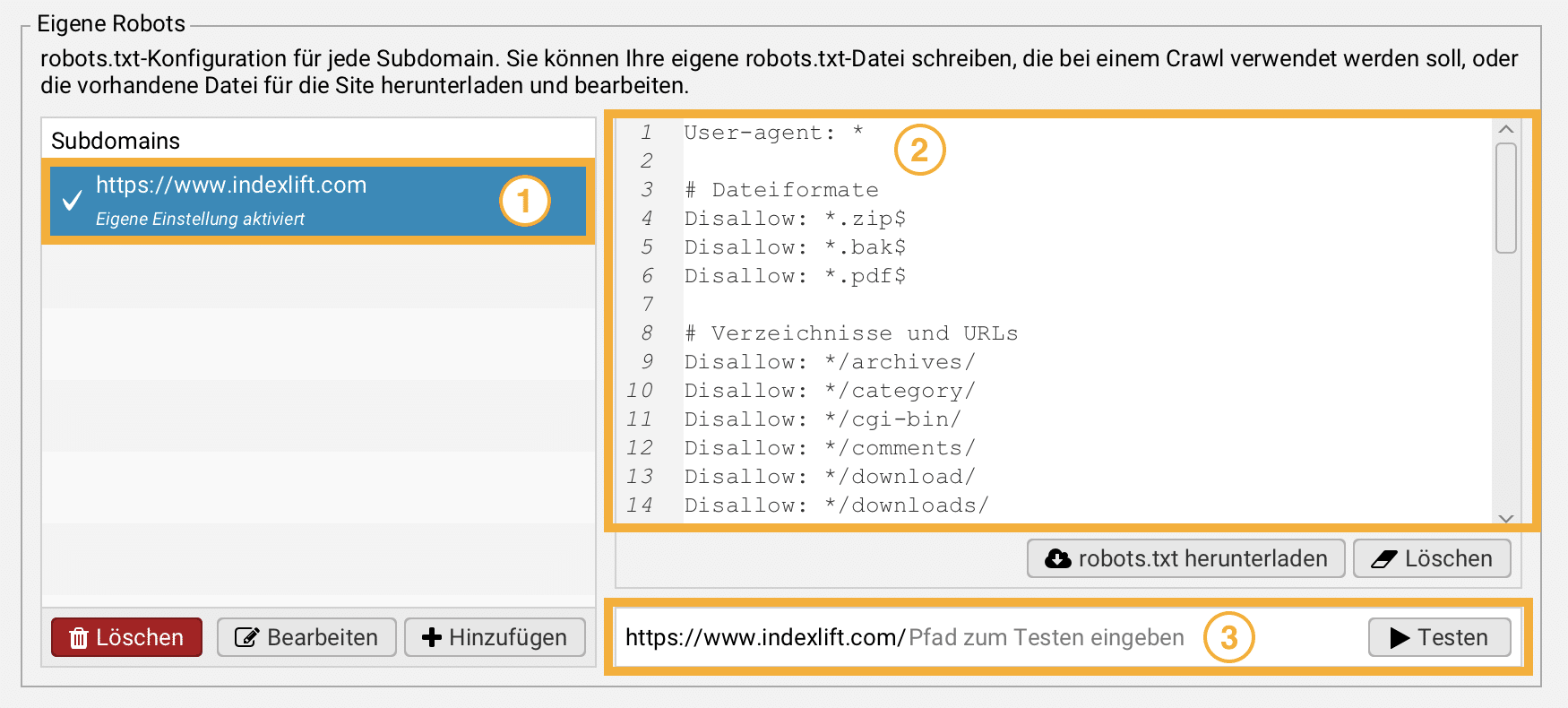
Tipp Du kannst individuelle robots.txt-Regeln erstellen und damit die serverseitigen Anweisungen überschreiben. Anschließend führst Du ein vollständiges Website Audit durch, um diese Regeln zu testen. Voraussetzung dafür ist, dass Du in der robots.txt-Konfiguration robots.txt respektieren auswählst.
URL-Prüfung mit der Google Search Console
Die Google Search Console stellt mit der Funktion URL-Prüfung eine Möglichkeit bereit, um verschiedene Google-relevante Informationen zu ermitteln, unter anderem ob das Crawling erlaubt ist. Du wählst URL-Prüfung (1) und gibst im Suchfeld (2) die absolute URL der Seite ein. Anschließend erhältst Du eine Information, ob das Crawling der Seite erlaubt ist (3).
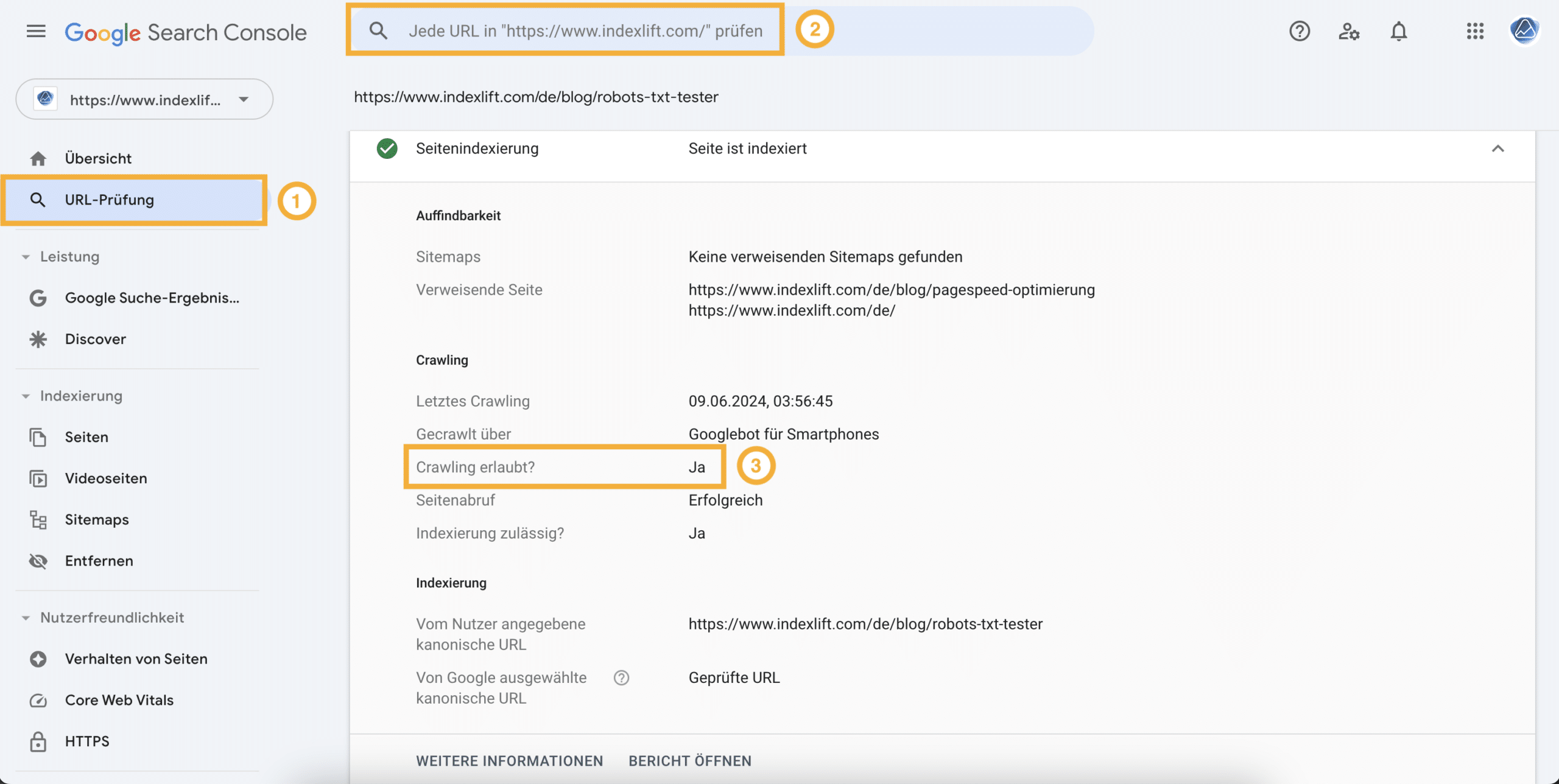
Leider wird nicht erklärt, welche robots.txt-Anweisung eine Seite vom Crawling blockiert:

robots.txt Generatoren
Im Web gibt es kostenfreie robots.txt Generatoren. Für die Erstellung von einfachen robots.txt-Regeln sind diese Generatoren hilfreich. Wenn fortgeschrittene Anweisungen nötig sind, ist die Erstellung der Regeln mit dem Screaming Frog die bessere Option.
- https://www.seoptimer.com/robots-txt-generator
- https://seranking.com/free-tools/robots-txt-generator.html




Hallo Jens,
vielen Dank für diesen informativen Artikel! Vielleicht noch ein Zusatzinfo, da hier oft eine falsche Annahme besteht. Ausschluss der robots.txt bedeutet nicht automatisch, dass die Seite nicht indexiert wird. Es kann trotzdem sein, dass die Suchmaschinen die Seite in deren Index aufnehmen.
Das ist richtig. Manche Suchmaschinen (und Scraper) halten sich prinzipiell nicht an das Robots Exclusion Protocol (REP) und verarbeiten alles, was gefunden wird. Google hält sich daran. Stellt Google fest, dass Seiten von der Verarbeitung/Indexierung ausgeschlossen werden, die Google selbst als relevant bewertet, dann indexiert sie Google willkürlich.