

Der Screaming Frog SEO Spider ist eines der mächtigsten Scraper auf dem Markt. Mit ihm können große Websites gecrawlt und tiefgründig analysiert werden. Er bietet umfassende Konfigurationsmöglichkeiten und Segmentierungen, Schnittstellen zu GA4, GSC, PageSpeed Insights, Ahrefs, Majestic und Moz.

Inhaltsverzeichnis
- Screaming Frog Bewertung
- Was bietet Screaming Frog SEO Spider?
- Woher hat der Screaming Frog seinen Namen?
- Was sind die größten Vorteile vom Screaming Frog?
- Was sind die größten Nachteile vom Screaming Frog?
- Wichtige Funktionen des Screaming Frog
- Zielgruppen
- Screaming Frog Modi
- SEO Spider Konfiguration
- Probleme-Protokoll
- Visualisierungen: Crawlbaumgraph
- Berichte exportieren
- Massenexport
- 🔥 Screaming Frog Anwendungstipps
- Screaming Frog Alternativen
Screaming Frog Bewertung

| Gesamt | 
|
4.5/5 |
| Benutzerfreundlichkeit | 
|
3.5/5 |
| Funktionsumfang | 
|
5/5 |
| Dokumentation (FAQ) | 
|
4/5 |
| Preis-Leistungs-Verhältnis |
|
5/5 |
| Empfehlungswahrscheinlichkeit |
|
5/5 |
Was bietet Screaming Frog SEO Spider?
Der Screaming Frog SEO Spider ist ein Crawler für tiefgründige SEO Audits. Er wird kostenlos zum Download für Windows-PC, MacOS und Linux angeboten.
Die gratis Version eignet sich allerdings nur zum Testen. Eine Pro-Lizenz kostet 245,00 EUR pro Jahr und Nutzer. Das bedeutet, dass ein Nutzer seine SEO Spider-Lizenz auf einem Desktop-PC und einem Laptap parallel nutzen kann.
Die Pro-Lizenz entsperrt alle Funktionen und hebt das Crawl-Limit von 500 URLs auf. Ab fünf Pro-Lizenzen wird Rabatt gewährt.
Woher hat der Screaming Frog seinen Namen?
Der Name Screaming Frog wurde von einem echten Frosch 🐸 inspiriert, der sich wehrte, nachdem er von zwei Katzen in Dan Sharps (Mitbegründer von Screaming Frog) Garten in die Enge getrieben wurde. Hier gibt es die komplette Story.
Was sind die größten Vorteile vom Screaming Frog?
Die größten Vorteile vom Screaming Frog sind sein enormer Funktionsumfang und das er große Websites vollständig crawlen kann.
Standardmäßig verwendet der SEO Spider RAM und nicht die Festplatte, um Daten zu speichern und zu verarbeiten. Er kann aber auch so konfiguriert werden, dass er die Crawl-Daten auf der Festplatte speichert, indem man den Modus Datenbankspeicherung auswählt, um in beispiellosem Umfang zu crawlen, während die gewohnten Echtzeitberichte und die Nutzerfreundlichkeit erhalten bleiben.

Das Standard Crawl-Limit liegt bei 5 Millionen URLs, aber das ist keine harte Grenze – der SEO Spider ist in der Lage, mehr zu crawlen (mit dem richtigen Setup). Ein PC mit einer 500 GB SSD (dringend empfohlen) und 16 GB RAM sollte es zum Beispiel erlauben, bis zu 10 Millionen URLs mit dem Screaming Frog zu crawlen.
Was sind die größten Nachteile vom Screaming Frog?
Der größte Nachteil ist sein Ressourcenverbrauch. Möchte man mit dem Screaming Frog große Websites (+500.000 URLs) crawlen, benötigt man einen leistungsstarken Computer. Denn der SEO Spider wird lokal installiert.
Er ist auch eher für erfahrene SEOs und Entwickler geeignet, da sich das SEO Spider Tool visuell von SaaS Tools (Software as a Service) unterscheidet, wie Audisto oder Sitebulb.
Das etwas sperrige Tabellenlayout und die mannigfaltigen Berichte erfordern auch ein wenig Einarbeitungszeit, doch dann wird man den Screaming Frog zu schätzen wissen.
Wichtige Funktionen des Screaming Frog
- Defekte Links, Fehler und Weiterleitungen identifizieren
- Analyse von Seitentiteln und Metadaten
- Daten mit XPath extrahieren
- XML-Sitemaps generieren
- JavaScript-Webseiten crawlen
- Zeitplan für Audits
- Weiterleitungen (-schleifen) auswerten
- Duplizierte Inhalte ermitteln
- Integration mit GA, GSC und PSI
- Visualisierung der Site-Architektur
- Crawls miteinander vergleichen
- Überprüfung Meta Robots & Richtlinien
- XML-Sitemaps bewerten
- Validierung von strukturierten Daten
- Rechtschreib- und Grammatikprüfung
- Benutzerdefinierte Quellcode-Suche mit Massen-Upload-Funktion
- Benutzerdefinierte Extraktion
- Standard- und Formularbasierte Authentifizierung (Staging)
- Raw und gerendertes HTML speichern und vergleichen
- Individuelle robots.txt-Konfiguration (robots.txt Check)
- AMP Crawling & Validierung
- Flesch-Lesbarkeitsbewertung
- Mobile Benutzerfreundlichkeit über die Lighthouse-Integration prüfen
- Lokale Lighthouse-Integration
- Segmente für individuelle Seitentypen oder Prioritätsbereiche
- Direkte KI-API-Integration
- Überprüfung der Barrierefreiheit (Validierung mit AXE-Regelsatz für Barrierefreiheit)
- E-Mail-Benachrichtigung über die Fertigstellung von Crawls
Zielgruppen
Vor allem technisch erfahrene Suchmaschinenoptimierer und Entwickler erhalten mit dem Screaming Frog alle Möglichkeiten, um ausführliche Website Audits zu erstellen.
Für Website-Betreiber und Marketing-Fachkräfte ohne technisches Verständnis sind die komplexen Konfigurationsmöglichkeiten und Berichte sicher etwas unübersichtlich. Es erfordert etwas Zeit, um das tabellenbasierte Interface zu verstehen und zu konfigurieren, die Crawl-Konfiguration durchzuarbeiten und die Crawl-Daten richtig zu interpretieren.
Screaming Frog Modi
Bei der ersten Anwendung fragt man sich meist, wie der Screaming Frog funktioniert. Er bietet fünf verschiedene Modi:
| Modus | Beschreibung |
| SEO Spider | SEO Spider ist der wichtigste Modus. Man legt eine URL als Ausgangspunkt für das Crawling fest, in der Regel die Startseite. Der Screaming Frog spidert diese URL und folgt den maschinenlesbaren Links im HTML-Code und spidert sich so durch die gesamte Website. Zuätzlich verarbeitet er URLs aus weiteren Quellen entsprechend der Crawl-Konfiguration. Die gesammelten Daten werden in Grafiken, Diagrammen und Tabellen dokumentiert. |
| Liste | Mit dem Listenmodus kann man eine vordefinierte URL-Liste überprüfen. Diese Liste kann aus einer Vielzahl von Quellen stammen – einfaches Einfügen aus der Zwischenablage oder der Upload einer .txt-, .xls-, .xlsx-, .csv- oder .xml-Datei. Die Dateien werden nach URLs mit den Präfixen http:// oder https:// durchsucht. Alle anderen Texte werden ignoriert. Man kann zum Beispiel einen Google Ads-Download in den SEO Spider hochladen und alle URLs werden automatisch gefunden. |
| SERP | Im SERP-Modus kann man den Seitentitel und die Seitenbeschreibung direkt in den SEO Spider hochladen, um Pixelbreiten (und Zeichenlängen) zu berechnen. In diesem Modus findet kein Crawling statt.
Das bedeutet, dass man die Seitentitel und Seitenbeschreibungen aus dem SEO Spider exportiert, sie in Excel bearbeitet und anschließend wieder in das Tool hochladen kann. Das dient dem Verständnis, wie diese Meta-Daten in den Google SERPs erscheinen könnten. |
| Vergleichen | Der Vergleichen-Modus ermöglicht es, zwei fertige Crawls zu vergleichen. Der Modus ist zum Beispiel bei einem Relaunch hilfreich, um das Testsystem mit der live-Website zu vergleichen oder um Änderungen vor und nach durchgeführten SEO-Maßnahmen zu vergleichen. |
| APIs | Im APIs-Modus kann man URLs hochladen und Daten von beliebigen APIs abrufen, ohne dass ein Crawling erfolgt. |
SEO Spider Konfiguration
Das Konfigurationsmenü vom Screaming Frog bietet im SEO Spider (früher: Crawl-Modus) umfassende Einstellmöglichkeiten für den Crawl. Es ist empfehlenswert, ausreichend Zeit zu investieren. Viele Crawl-Einstellungen besitzen Tooltips, um die jeweilige Einstellung zu erklären.

| Konfiguration | Beschreibung |
| Spider | Im Spider-Menü werden grundlegende Einstellungen zum Crawl-Verhalten vorgenommen, welche Linktypen gecrawlt und gespeichert werden sollen. Man kann festlegen, welche Elemente und Daten während des Crawls analysiert, extrahiert und gespeichert werden sollen. Limits können individuell festgelegt werden – wie die Anzahl zu crawlender URLs oder die Crawltiefe. Zusätzlich können wichtige Einstellungen zum JS-Rendering eingestellt werden. |
| Inhalt | Hier kann man konfigurieren, wie der SEO Spider den Inhalt der gecrawlten Seiten analysiert. Man kann den Inhaltsbereich individuell bestimmen, den Umgang mit Duplikaten (doppelte Inhalte) festlegen und optional eine Rechtschreib- und Grammatikprüfung konfigurieren. |
| robots.txt | Hier kann man festlegen, ob die Anweisungen der robots.txt-Datei auf dem Server ignoriert werden sollen, bzw. wie die Daten auszuschließender Ressourcen in den Reports dargestellt werden sollen. Optional kann eine temporäre robots.txt-Datei für den Crawl erstellt und damit die Anweisungen auf dem Webserver überschrieben werden. |
| URL-Umschreibung | Mit dieser Einstellung kann man die von SEO Spider gecrawlten URLs umschreiben. Das kann nützlich sein, um unnötiges Crawlen zu vermeiden und die Crawl-Zeit spürbar zu reduzieren. Besonders bei großen Websites mit mehreren Millionen URLs ist das hilfreich. |
| CDNs | Werden verschiedene Ressourcen per CDN eingebunden, kann hier eine Liste von Subdomains und Verzeichnissen notiert werden, damit diese Ressourcen beim Crawlen erfasst und als intern betrachtet werden. |
| Einbeziehen | Hier können Regular Expressions für URLs festgelegt werden, die beim Crawling zu beachten sind. |
| Ausschließen | Hier können Regular Expressions für auszuschließende URLs hinterlegt werden. |
| Geschwindigkeit | Diese Einstellungen konfigurieren die Crawl-Geschwindigkeit des SEO Spiders über die Anzahl gleichzeitiger Threads, sowie über die Anzahl der URLs, die pro Sekunde angefragt werden. |
| Benutzer Agent | Hier kann man den User-Agent festlegen, den SEO Spider für den Crawl verwendet. Entsprechend werden die robots.txt Regeln beachtet. |
| HTTP Header | Man kann die HTTP-Header anpassen, die SEO Spider für den Crawl verwendet. So können beliebige Header oder Werte angegeben werden – wie Accept-Language, Cookie, Referer. |
| Eigene | Eigene Suche ist eine einfache Suchfunktion im Quellcode von HTML Seiten oder PDFs. Damit können einfache Regular Expressions festgelegt werden.
Die Benutzerdefinierte Extraktion ermöglicht es, mithilfe von XPath, CSS-Pfad oder RegEx Daten aus internen HTML Seiten zu extrahieren. |
| API Zugang | Screaming Frog bietet Möglichkeiten, URL-Daten verschiedener Dienste per API zu beziehen und diese URLs zu spidern: Google Universal Analytics, Google Analytics 4, Google Search Console, PageSpeed Insights, Ahrefs, Majestic, Ahrefs, Moz, OpenAI, Gemini, Ollama. |
| Authentifizierung | Geschützte Bereiche können mit Screaming Frog gespidert werden. Die Authentifizierung kann standardbasiert oder Webformular-basiert erfolgen. |
| Segmente | Durch eigene Segmente können Schwerpunktbereiche festgelegt werden. So können die Crawl-Daten individuell gefiltert und eingeschränkt werden. |
Probleme-Protokoll
Gut gelöst finde ich das Probleme-Protokoll, das eine Übersicht wichtiger Prüfkriterien liefert, um einen schnellen Überblick zu Problemen und Warnungen zu erhalten. Man öffnet es in der Reiter-Navigation Probleme vom Übersicht-Reiter.
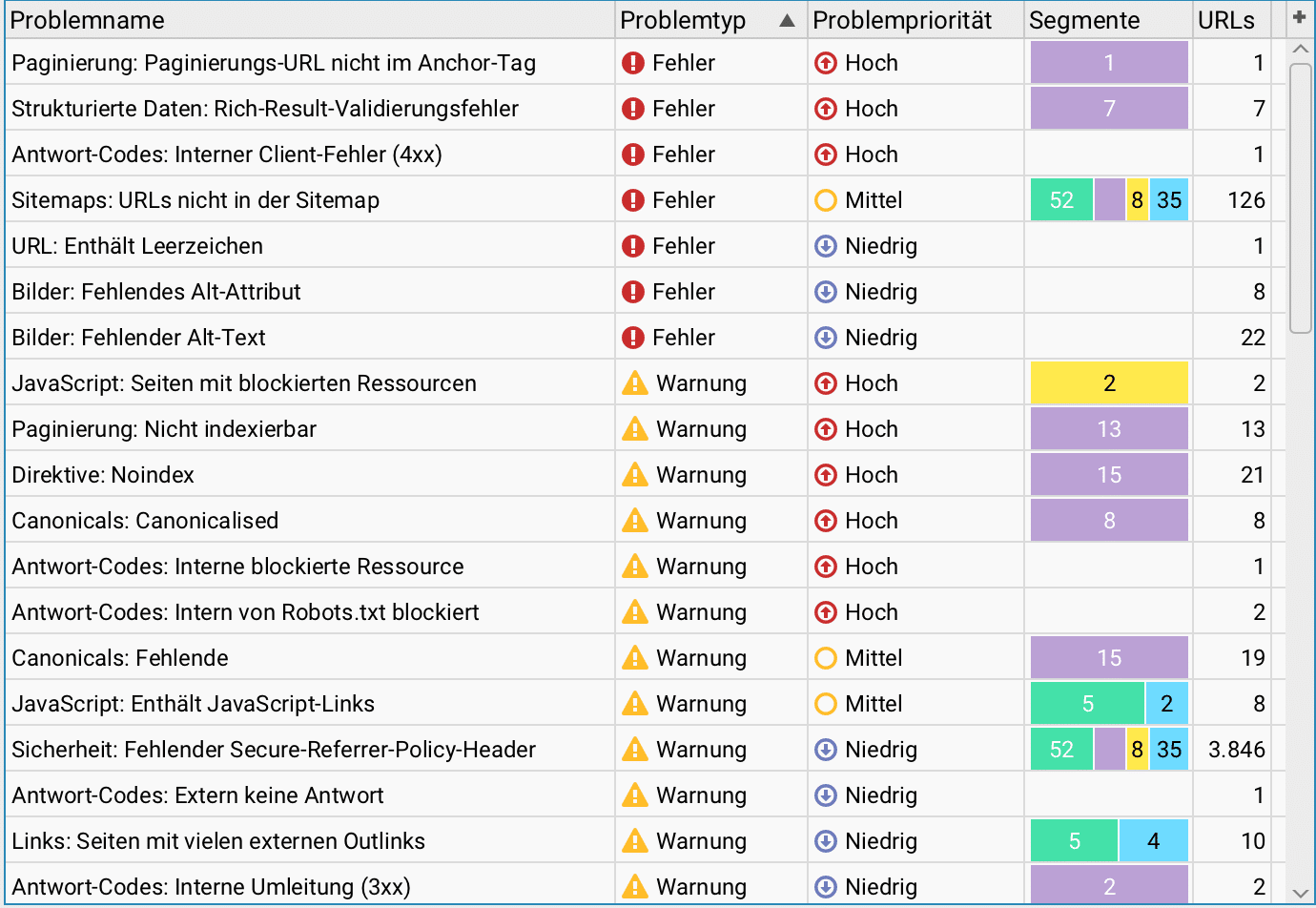
Was ist der Übersicht-Reiter?
Im Screaming Frog befindet sich der Übersicht-Reiter auf der rechten Seite und listet alle Prüfkriterien des Crawls auf. Durch Klicken auf ein Prüfkriterium öffnet man die jeweilige Datentabelle.
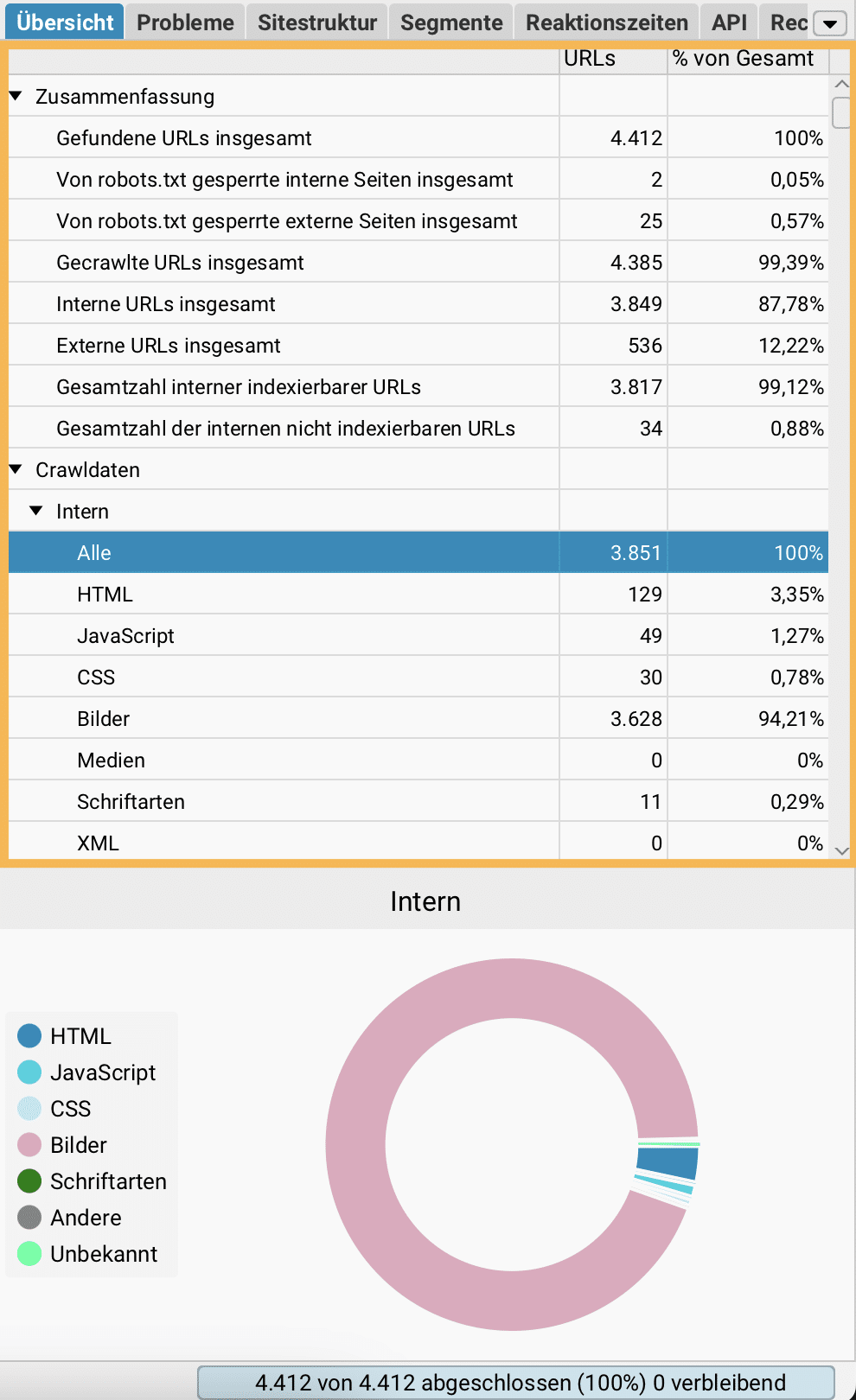
Visualisierungen: Crawlbaumgraph
Screaming Frog bietet verschiedene Visualisierungen für eine gecrawlte Website an. Den Crawlbaumgraph finde ich am hilfreichsten, um die Website-Architektur zu visualisieren.
Der Crawlbaumgraph zeigt an, wie der SEO Spider eine Website gecrawlt hat, und zwar nach dem kürzesten Pfad zu einer Seite von der Start-URL. Er zeigt nicht jeden internen Link, weil das die Visualisierungen schwer skalierbar und unverständlich machen würde. Wenn eine Seite mehrere Links aus der gleichen Tiefe besitzt, wird derjenige Link angezeigt, der zuerst gecrawlt wurde. Die Crawl-Visualisierungen sind hierarchisch nach Crawl-Tiefe geordnet, und die Linien zwischen URLs stellen den kürzesten Pfad dar. Das macht den Crawlbaumgraph sehr nützlich für die Analyse der Website-Architektur und der internen Verlinkung.

Berichte exportieren
Sobald ein Crawl abgeschlossen ist, können alle Datentabellen exportiert werden. Dazu klickt man auf den Export-Button (oranger Rahmen im Screenshot), um alle Daten eines Berichts zu exportieren.
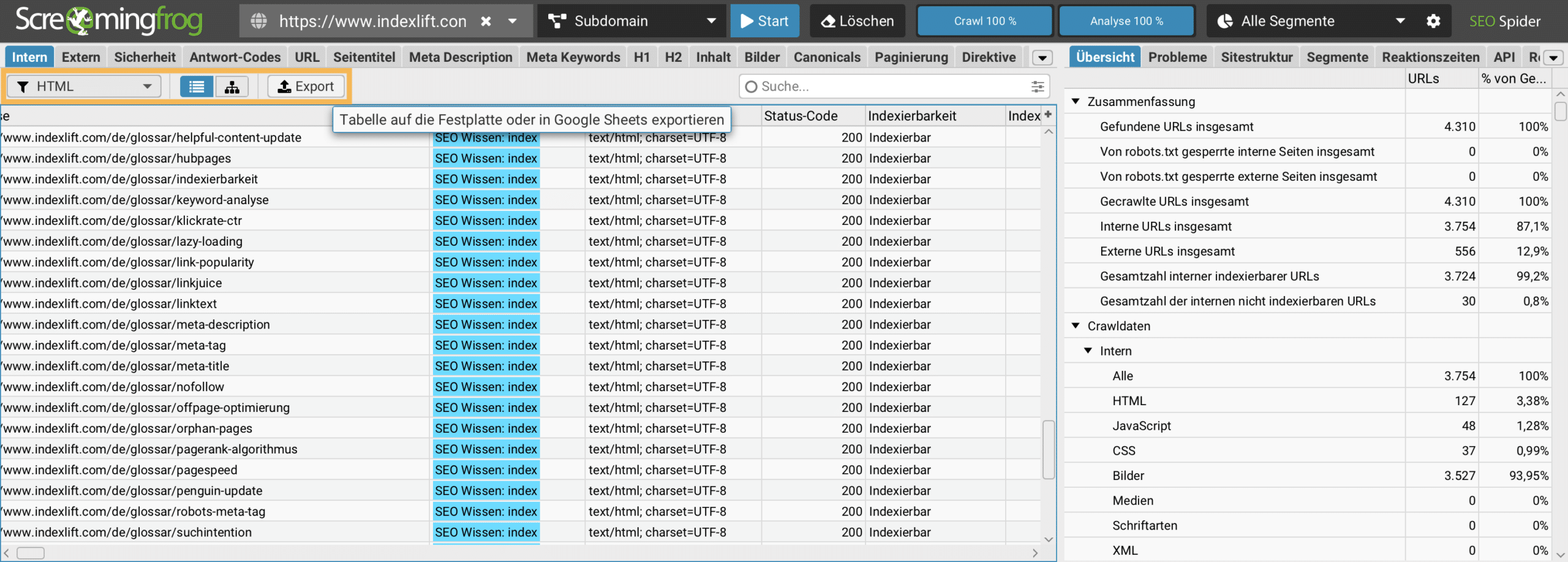
Massenexport
Analog zu den Reports können verschiedene vordefiniertes Massenexports erstellt werden, um die Crawl-Daten in Excel oder einem anderen Programm (Apple Numbers) weiter zu bearbeiten. Massenexports können im Hauptmenü aufgerufen werden.

🔥 Screaming Frog Anwendungstipps
- Nicht crawlbare URLs ermitteln
- Nicht indexierbare URLs ermitteln
- Interne Client-Fehler (4xx) ermitteln
- Kanonisierte URLs ausschließen
- Insecure Content aufdecken
- Strukturdaten auswerten
- SERP Snippets analysieren
- Externe Dienste per API einbinden
- Orphan URLs (verwaiste Seiten) ermitteln
- Geschützte Testumgebung crawlen
- Interne Suche vom Screaming Frog
- Include und Exclude Filter erstellen
- Custom Extraction-Filter verwenden
- URL-Liste exakt crawlen
- Statische XML Sitemap erstellen
- Crawl-Limit vom SEO Spider
Wie kann man mit Screaming Frog nicht crawlbare URLs ermitteln?
Bei jedem professionellen SEO-Audit wird die Crawlbarkeit interner URLs geprüft. Vor einem Website-Crawl empfehle ich eine Konfiguration zu wählen, dass die robots.txt-Anweisungen beachtet werden: Konfiguration > robots.txt > robots.txt respektieren auswählen. Die betreffenden URLs werden im Übersicht-Reiter Antwort-Codes > Von robots.txt gesperrt inkl. der Anweisung dokumentiert. Fehlkonfigurationen können somit schnell ermittelt werden.
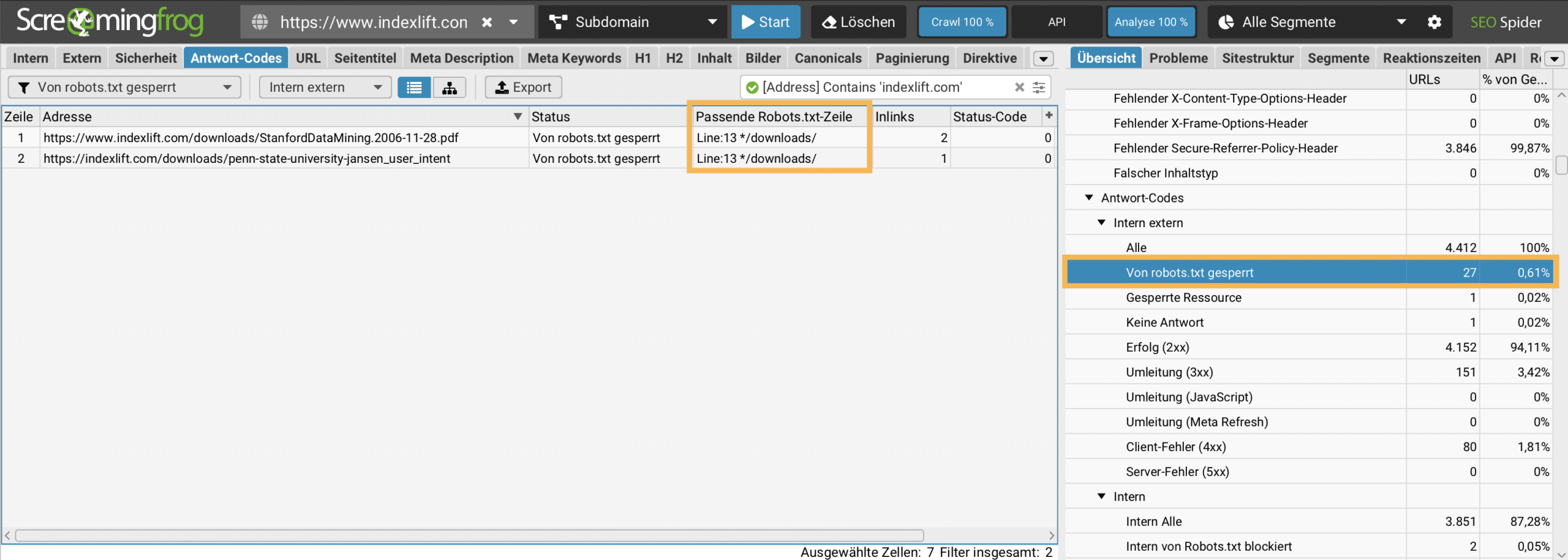
Möchte man die robots.txt-Anweisungen auf dem Webserver überschreiben, ist das in den robots.txt-Einstellungen der Crawl-Konfiguration möglich. unter Eigene Robots werden die individuellen Anweisungen notiert. Diese Anweisungen kann man vor dem Crawling testen.
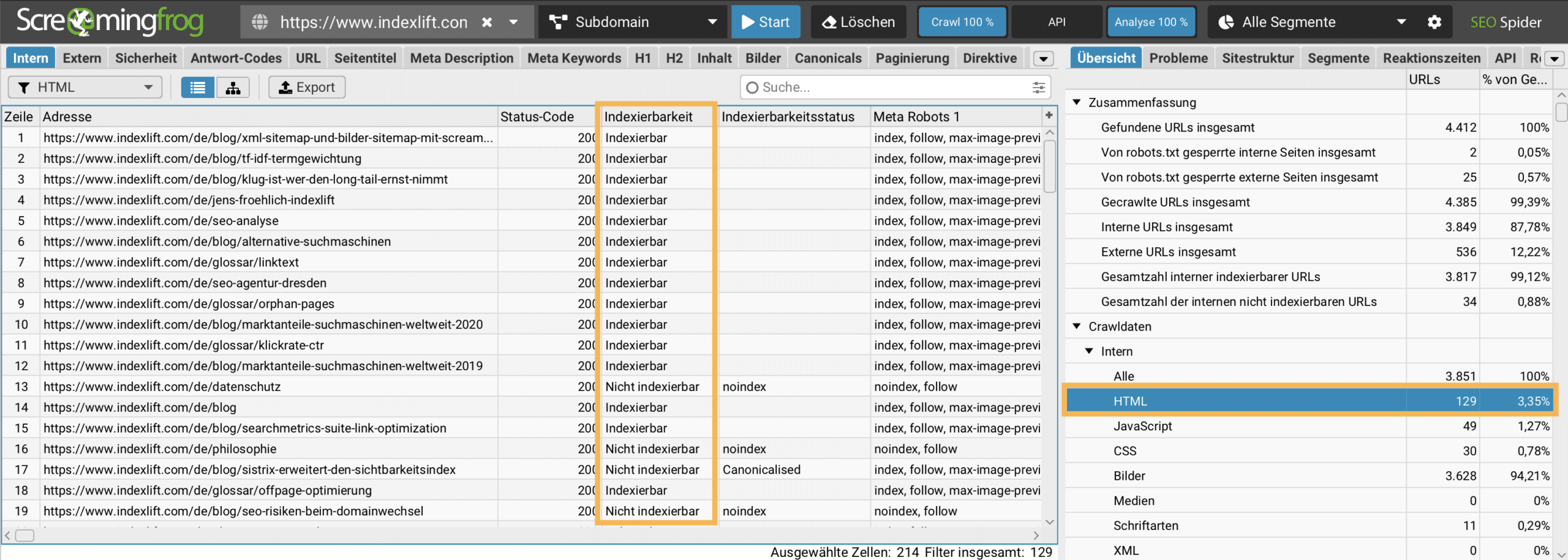
Wie kann man mit Screaming Frog nicht indexierbare URLs ermitteln?
Alle crawlbaren URLs sollten bei einem SEO Audit bezüglich deren Indexierbarkeit analysiert werden, um zu ermitteln, ob relevante Seiten durch technische Fehlkonfigurationen (Meta Robots Tag/ Canonical Tag) vom Indexieren ausgeschlossen werden. Die Daten lassen sich im SEO Spider-Modus ermitteln.
Wie kann man mit Screaming Frog interne Client-Fehler (4xx) ermitteln?
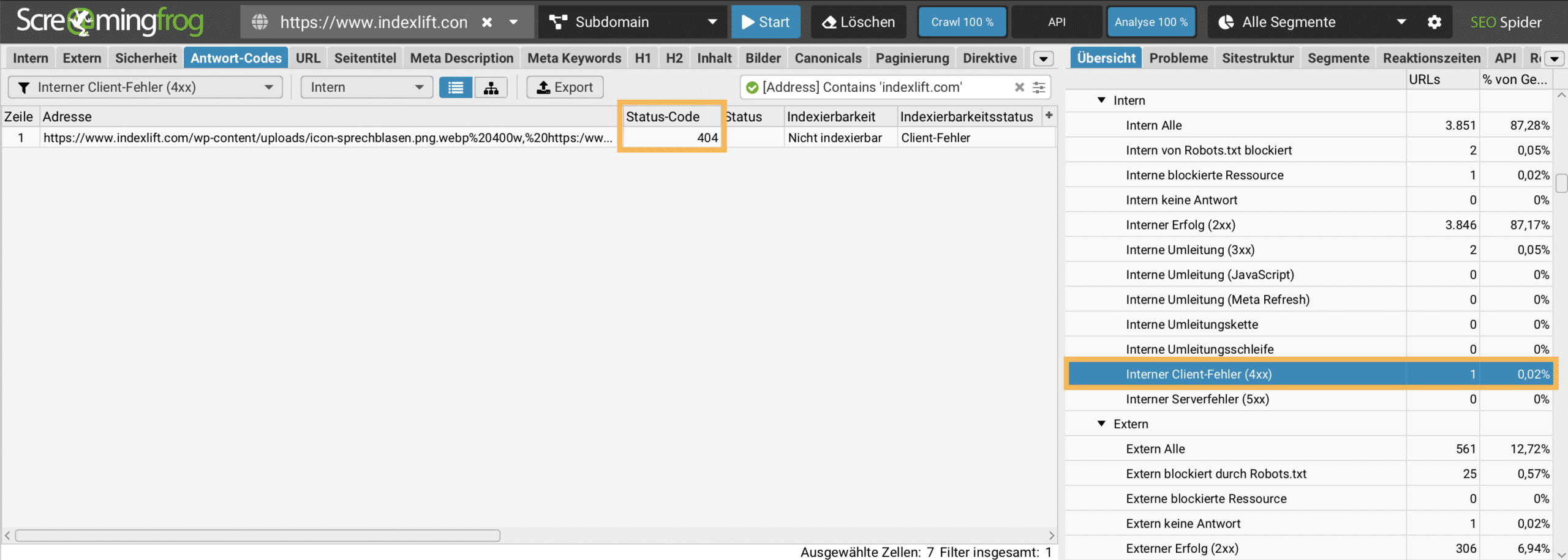
Der Bericht Interne Client-Fehler (4xx) unter Antwort-Codes im Übersicht-Reiter listet alle URLs auf, die nicht verfügbar sind und einen HTTP Statuscode 4xx generieren. Auf diesen Seiten ist die Absprungrate sehr hoch. Deshalb sollten interne Verlinkungsfehler vermieden werden. Bei jedem Crawling sollten diese Daten analysiert und Fehler korrigiert werden.
Wie kann man mit Screaming Frog kanonisierte URLs ausschließen?
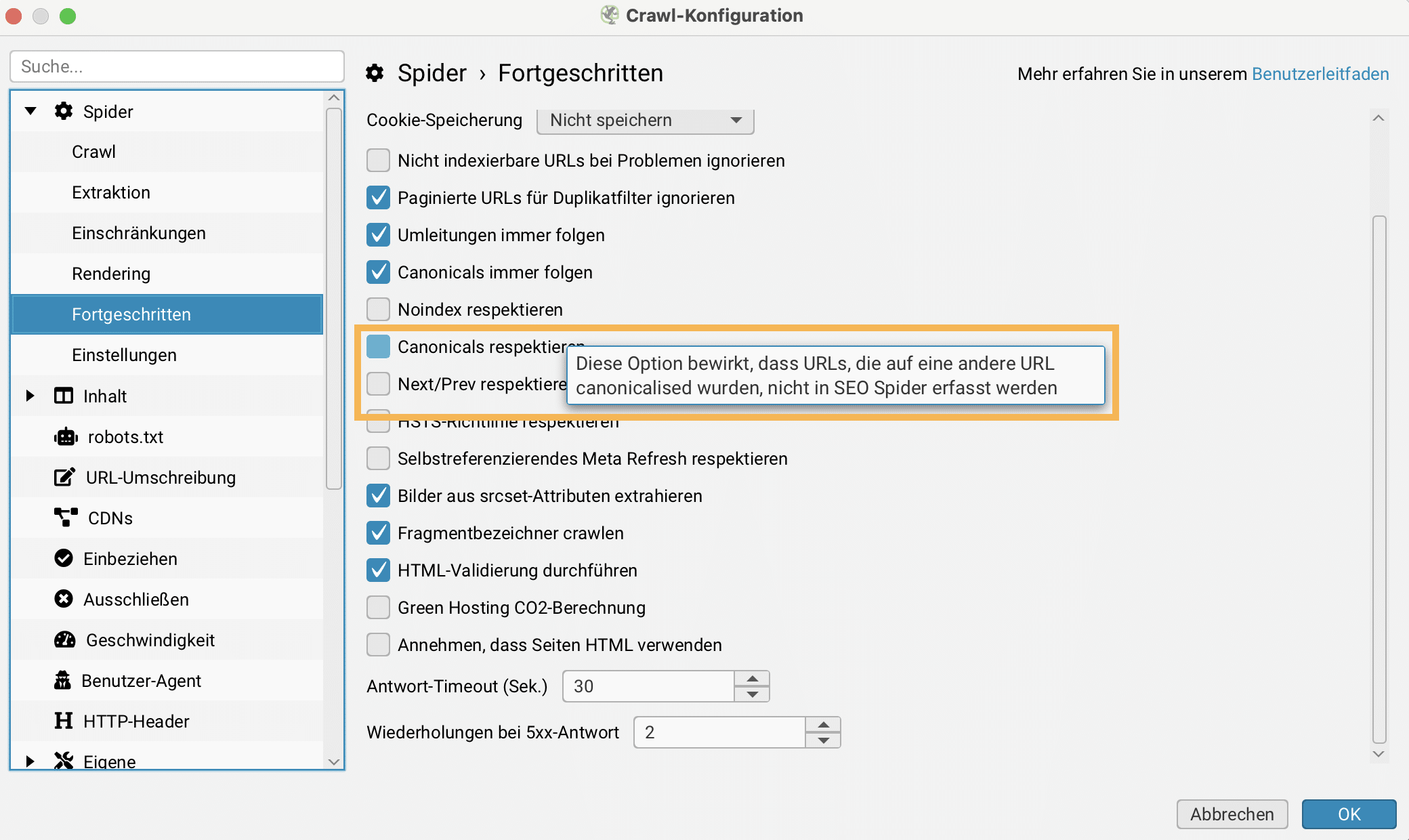
Wenn große Websites gecrawlt werden und der Fokus auf indexierbaren URLs liegt, hilft die Funktion Canonicals respektieren – über Konfiguration > Spider > Fortgeschritten. Diese Einstellung bewirkt, dass URLs, die eine andere URL kanonisieren, nicht vom SEO Spider erfasst werden.
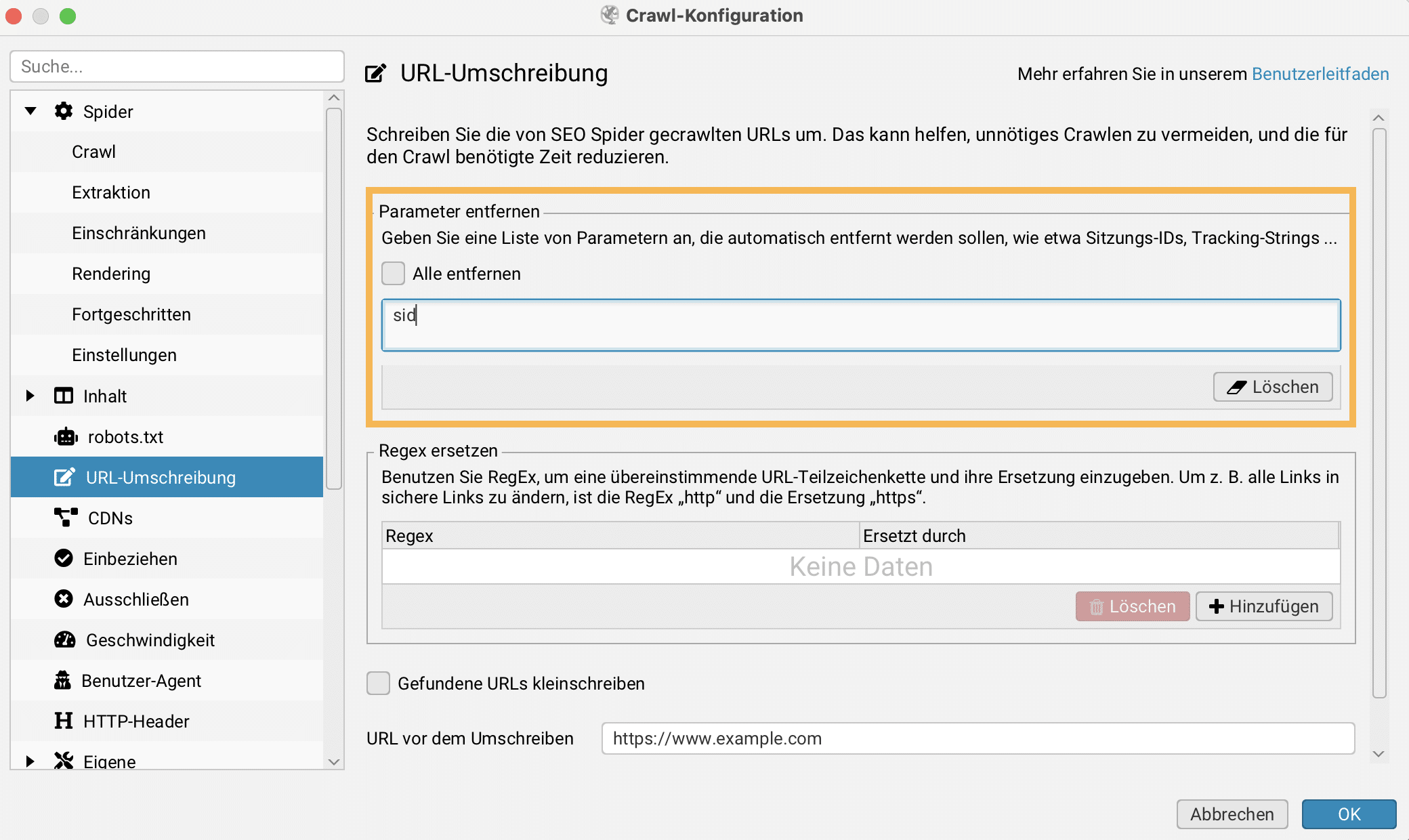
Sind alle Get-Parameter der Website bekannt, die aufgrund von Canonical Tags nicht gecrawlt werden sollen, bietet sich die Verwendung der Funktion URL-Umschreibung an. (Konfiguration > URL-Umschreibung > Parameter entfernen) Pro Zeile kann ein Parameter notiert werden, den der Screaming Frog beim Crawlen ignorieren soll. Ein Beispiel ist der Parameter ?sid= der oft in Shopware gesichtet wird. Sollen diese URLs beim Spidern nicht erfasst werden, dann braucht nur sid hinterlegt zu werden.
Wie kann man mit Screaming Frog Insecure Content aufdecken?
Dass HTTPS heute Standard für jede Website ist, sollte bekannt sein. Screaming Frog bietet einen Filter, um URLs zu identifizieren, die intern nicht per HTTPS verlinkt sind und korrigiert werden sollten. Dieser Filter befindet sich rechts im Overview unter Sicherheit > HTTP-URLs.
Wie kann man mit Screaming Frog Strukturdaten auswerten?
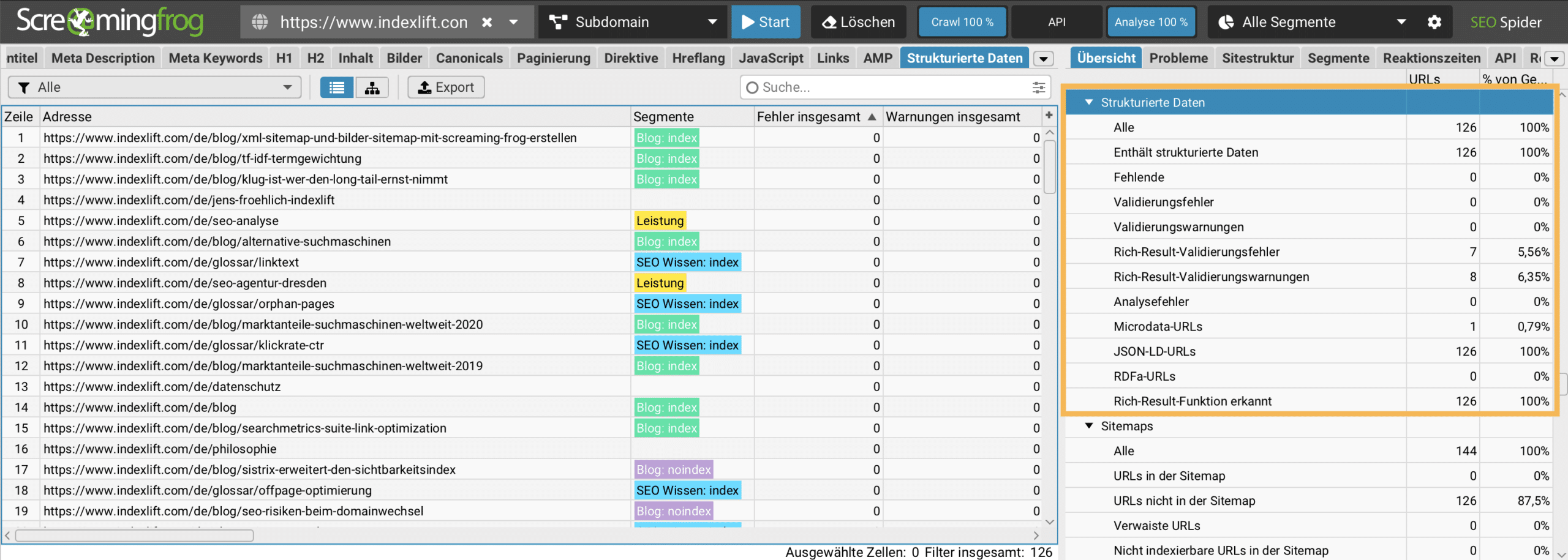
Seit Version 11 liest der Screaming Frog Structured Data aus. Diese Filter sind interessant, wenn der technische und OnPage Optimierungsgrad der Website hoch ist, keine internen Fehler bestehen, Seitentitel, Seitenbeschreibung, Headlines und Images optimiert sind und natürlich die Indexierungslogik optimal ausgerichtet ist.
Die Strukturdaten sind im Übersicht-Reiter unter Strukturierte Daten zu finden. Besonders hilfreich sind die Filter, um Validierungsfehler und Warnungen zu ermitteln.
Wie kann man mit Screaming Frog SERP Snippets analysieren?
SERP Snippets sind der erste Kontaktpunkt mit dem Suchmaschinen-Nutzer. Deshalb sollten indexierbare Seiten einen optimalen Seitentitel und eine optimale Seitenbeschreibung erhalten. Mit dem Screaming Frog lassen sich diese Daten schnell auswerten. Ich verwende dafür gern den Bericht Intern > HTML im Übersicht-Reiter.
In der unteren Reiter-Navigation befindet sich unter SERP-Ausschnitt ein SERP Snippet Tool, mit dem der Seitentitel und die Seitenbeschreibung einer Seite bewertet werden kann. Man kann temporär ein besseres SERP Snippet erstellen und verschiedene Darstellungen testen.

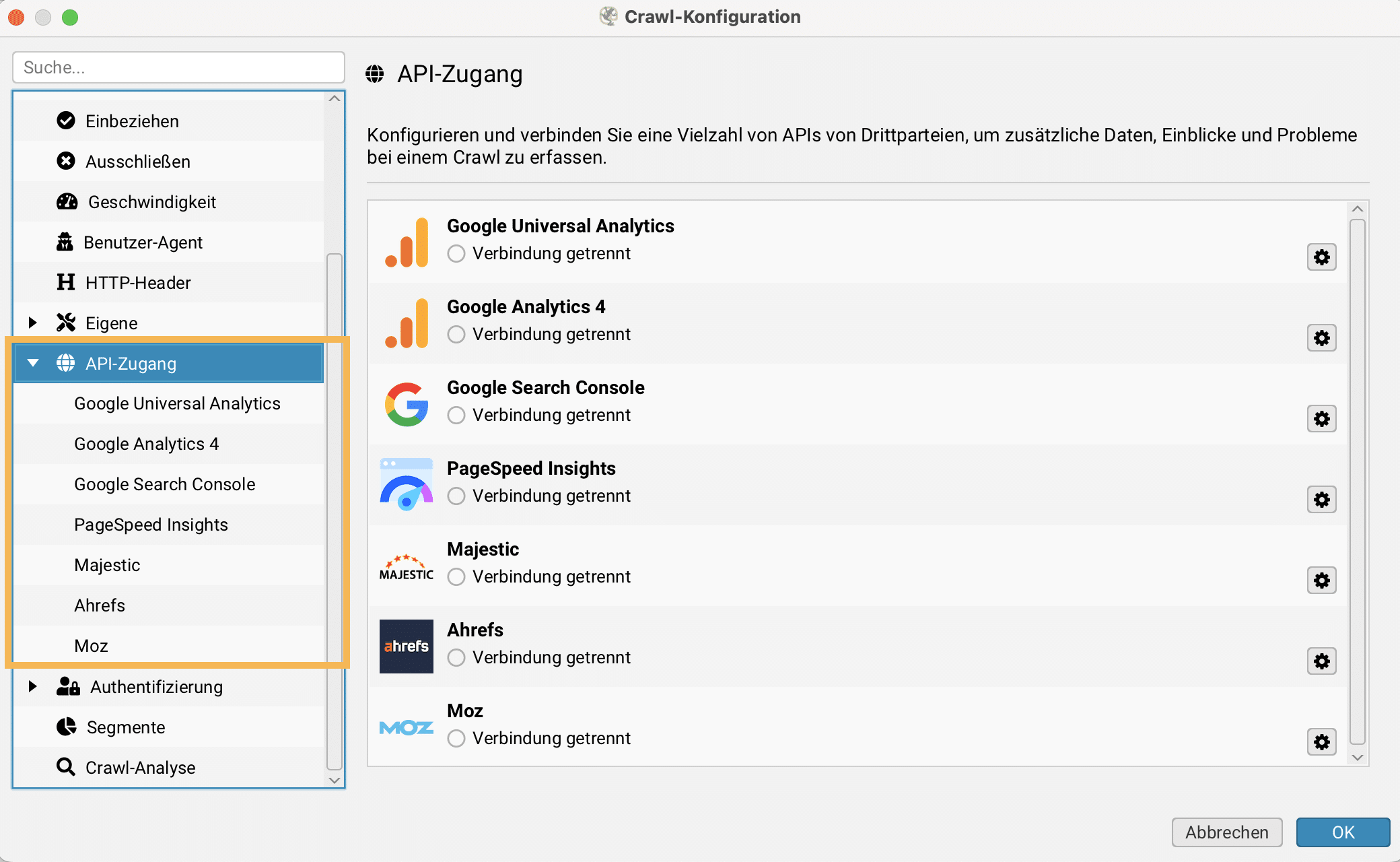
Kann man mit Screaming Frog externe Dienste per API einbinden?
Screaming Frog kann im SEO Spider-Modus API-Daten von externen Diensten einbinden: Google Universal Analytics, Google Analytics 4, Google Search Console, Ahrefs, Majestic und Moz. Jeder Dienst muss verifiziert werden.
Wie kann man mit Screaming Frog Orphan URLs (verwaiste Seiten) ermitteln?
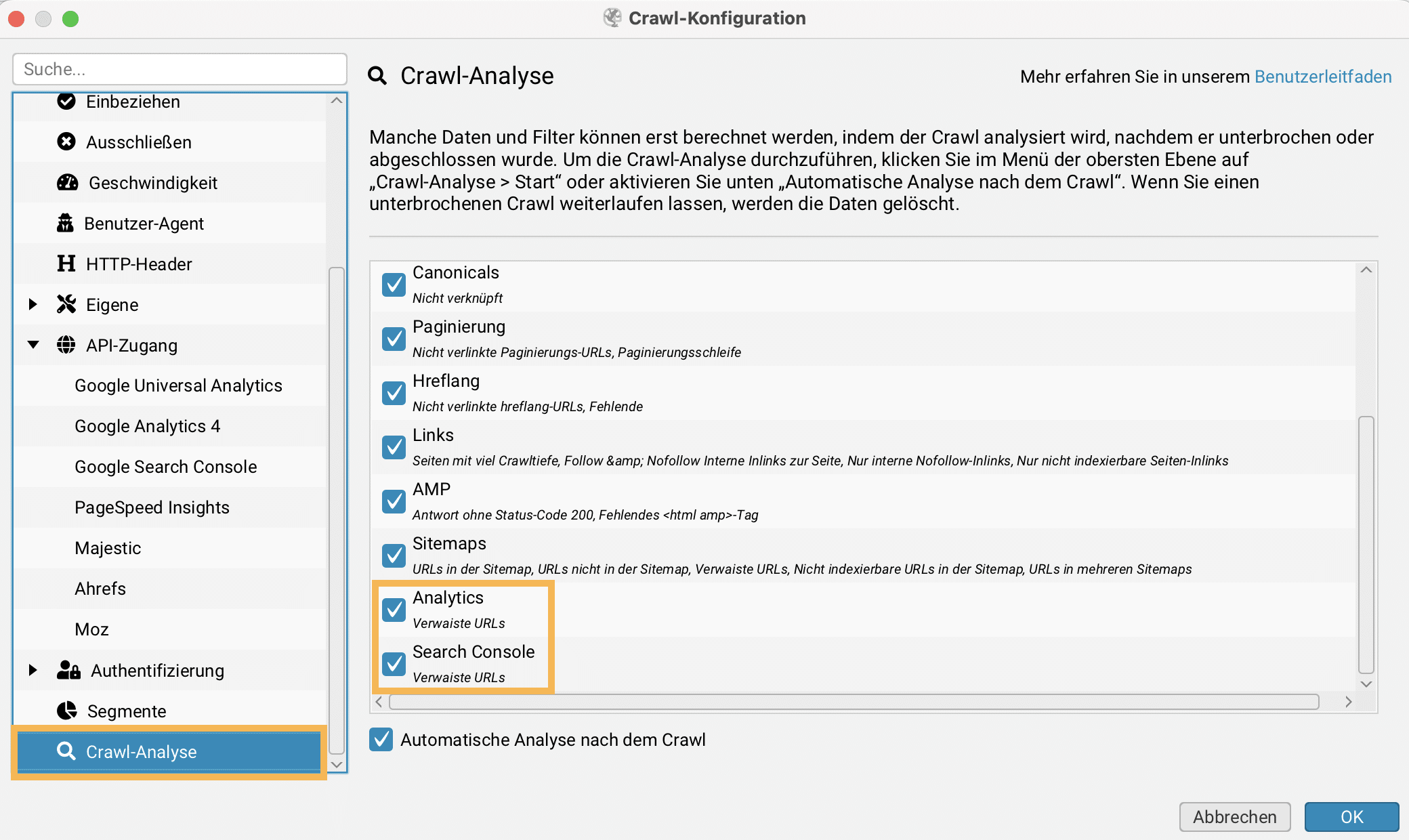
Als Orphan URLs (Verwaiste Seiten) werden in der Suchmaschinenoptimierung Seiten bezeichnet, die durch eine schlechte interne Verlinkung nicht von Suchmaschinen-Bots gefunden und nicht verarbeitet werden können. Mit Screaming Frog SEO Spider können Orphan URLs enttarnt werden. Voraussetzung hierfür ist die Verwendung der Google Analytics-API oder der Search Console-API, sowie nach dem abgeschlossenen Crawl die Durchführung einer Crawl-Analyse.
Wie kann man mit Screaming Frog eine geschützte Testumgebung crawlen?
Mit Screaming Frog SEO Spider können geschützte Testumgebungen (Standardbasiert oder Formularbasiert) gecrawlt werden. Die Zugangsdaten gibt man in der Crawl-Konfiguration unter Authentifizierung vor dem Crawling ein.

Besitzt Screaming Frog eine interne Suche?
Die interne Suchfunktion ist ein mächtiges Feature vom Screaming Frog SEO Spider. Hier können Daten gesucht werden, zum Beispiel alle Adressen, die einen bestimmten Begriff besitzen. Im Suchfeld können sogar reguläre Ausdrücke (Regular Expression) verwendet werden – ein paar Beispiele:
| Regulärer Ausdruck | Haken bei | Funktion |
| .html$ | Address | Alle URLs, die mit .html enden |
| (?i)LTE(?-i) | Address | Alle URLs mit dem regulären Ausdruck LTE (Großbuchstaben) |
| ^4 | Status Code | Alle URLs, deren Statuscode mit 4 beginnt |
Wie kann man mit Screaming Frog Include und Exclude Filter erstellen?
Include Filter eignen sich immer dann, wenn bestimmte Teilbereiche einer Website gecrawlt werden sollen. Angenommen eine Website wird in mehreren Sprachen bereitgestellt. Jede Sprachversion befindet sich in einem Verzeichnis (z. B. /de/ und /en/ und /fr/). Soll nur eine bestimmte Sprachversion der Website untersucht werden, hinterlegt man vor dem Crawling einen Include-Filter – zum Beispiel für das Verzeichnis /de/.

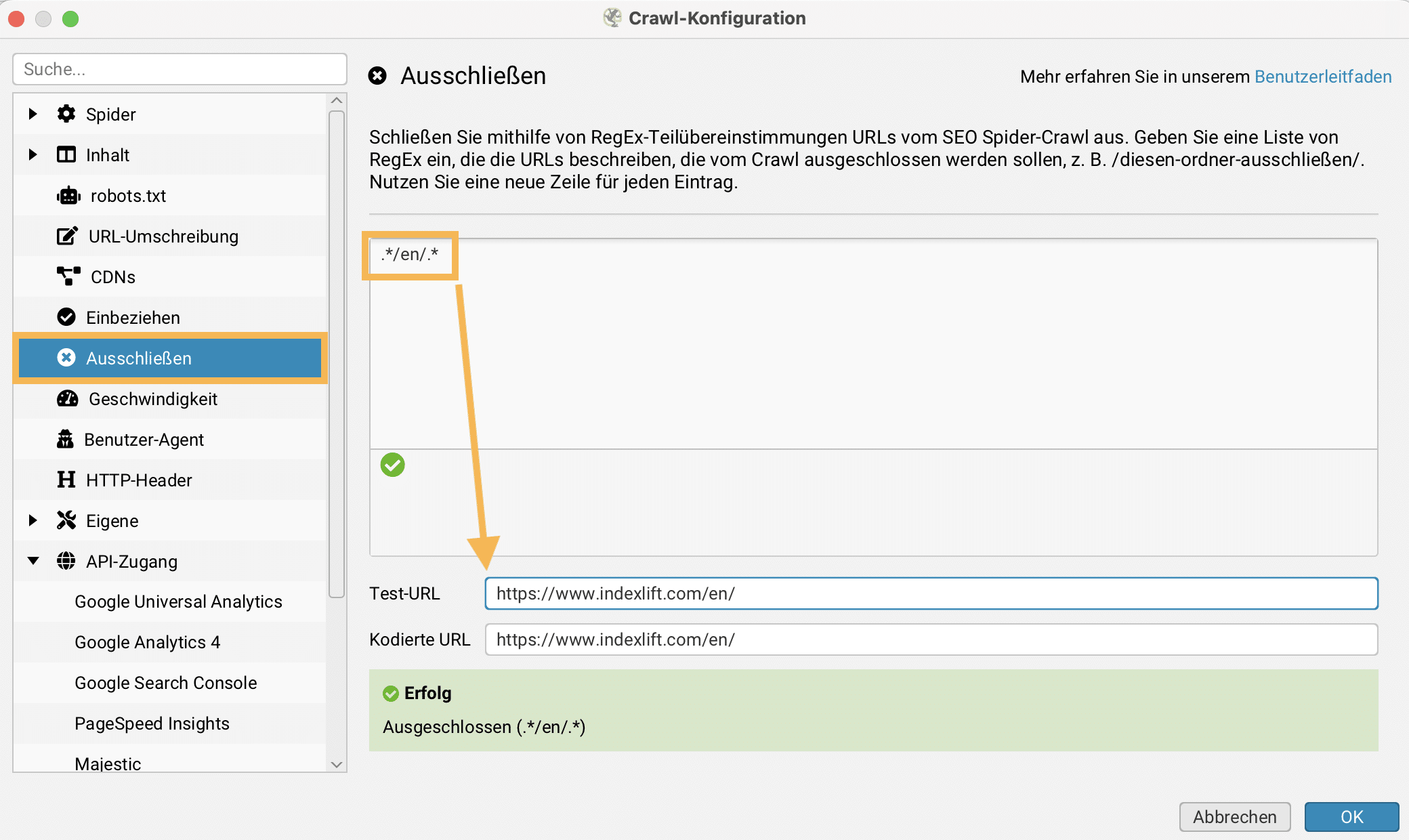
Im Gegensatz können für einen Crawl auch Exclude-Filter definiert werden, sodass bestimmte URLs und Verzeichnisse beim Crawlen ignoriert werden. In meinem Beispiel werden alle URLs mit dem Pfad /en/ ignoriert. Es können mehrere Excludes festgelegt werden. Pro Zeile wird ein Exclude-Filter notiert.
Wie kann man den Custom Extraction-Filter von Screaming Frog verwenden?
Durch Custom Extraction Filter können individuelle Filter für einen Crawl definiert werden. Diese mächtige Funktion befindet sich im Hauptmenü unter Konfiguration > Eigene > Benutzerdefinierte Extraktion. Wer technisch erfahren ist, kann sehr hilfreiche Filter erstellen.

Die Daten werden im Übersicht-Reiter unter Benutzerdefinierte Extraktion > bereitgestellt.

Wie kann man mit Screaming Frog eine URL-Liste exakt crawlen?
Soll eine URL-Liste gecrawlt werden, bei der ausschließlich die angegebenen URLs gecrawlt werden sollen, dann hilft folgender Tipp:
- Listen-Modus auswählen
- File > Configuration > Clear Default Configuration
- Upload auswählen und URL-Liste hochladen oder aus Zwischenablage einfügen
- Start
Clear Default Configuration löscht alle individuellen Konfigurationen. Zuvor sollte ein Backup der eigenen Default-Settings erfolgen: File > Configuration > Safe As…
Wie kann man mit Screaming Frog eine statische XML Sitemap erstellen?
Wenn der Crawl 100 Prozent erreicht hat und abgeschlossen ist, klickt man auf die Option XML-Sitemap unter Sitemaps im Menü auf der obersten Ebene. In der Konfiguration des Sitemap-Exports kann man nun die Anforderungen der XML Sitemap bestimmen. Beachtet werden muss, dass Sitemaps ausschließlich URLs mit einem 200-Statuscode und indexierbare (kanonische) Seiten enthalten.
Sobald alle gewünschten Einstellungen vorgenommen sind, klickt man auf den Button Exportieren,um die Sitemap auf dem Computer zu speichern. Die XML-Sitemap ist nun bereit, an die Suchmaschinen übermittelt zu werden. Ich empfehle, die Sitemap über die Search Console an Google zu übermitteln, um die Indexierung zu verfolgen.
Wie viel Millionen URLs kann man mit Screaming Frog crawlen?
Screaming Frog ist ein leistungsstarkes SEO-Tool, das Webseiten detailliert durchsuchen kann, um auch die Seitenstruktur zu analysieren. Die Anzahl der URLs, die mit Screaming Frog gecrawlt werden können, hängt von vielen Faktoren ab, einschließlich der verfügbaren Systemressourcen und der Lizenz. Mit der kostenpflichtigen Version gibt es keine festgelegte Grenze für die Anzahl der URLs, die gecrawlt werden können. Praktische Grenzen werden jedoch durch die Speicherkapazität und Leistungsfähigkeit des verwendeten Computers bestimmt. Für umfangreiche Projekte empfiehlt es sich, die Optimierung der vorhandenen Ressourcen zu beachten, indem der Crawl auf die notwendigen Daten beschränkt wird. Ein PC mit einer 500 GB SSD und 16 GB RAM sollte bis zu 10 Millionen URLs crawlen können.
Screaming Frog Alternativen
Für mich ist der Screaming Frog SEO Spider der fast perfekte Website Crawler. Nur die lokale Installation und das etwas sperrige Tabellenlayout dämpfen die Nutzerzufriedenheit anfangs. Doch JavaScript-Crawling und -Rendering, Export-Möglichkeiten, ein enormer Funktionsumfang und die Möglichkeit Websites mit Millionen URLs zu crawlen, machen den Screaming Frog fast konkurrenzlos.
Empfehlenswerte Alternativen, die ich mit einem guten Gefühl empfehlen kann, sind folgende Tools: Audisto Crawler und Sitebulb.




Kommentar verfassen