

XPath ist eine Abfragesprache, um Teile von XML-Dateien zu adressieren und auszuwerten. XPath kann beim SEO Spider Screaming Frog genutzt werden: Individuelle XPath-Filter ermöglichen vielseitige Analysen im HTML-Code. In diesem Blog-Beitrag stelle ich hilfreiche XPath-Filter vor, die man direkt im Screaming Frog verwenden kann.

Mit dem Screaming Frog SEO Spider kann man HTML-Code und Textinhalte extrahieren. Die Crawl-Software besitzt eine Custom Search-Funktion für einfache Textsuchen. Doch viel mächtiger sind die Custom Extraction-Funktionen, mit denen ausgewählte Elemente von internen HTML-Seiten extrahiert werden können. Der SEO-Spider unterstützt die folgenden Modi zur Datenextraktion: »XPath«, »CSS Path« und »Regex«.
Inhaltsverzeichnis
XPath Custom Extraction-Filter erstellen
- Screaming Frog SEO Spider (Lizenziert) öffnen
- Im Menü »Configuration« > »Custom« > »Extraction« auswählen
- Nun können individuelle XPath Custom Extraction-Filter erstellt werden
Wenn man »XPath« oder »CSS Path« verwendet, kann man auswählen, was extrahiert werden soll:
| Abfrage | Ausgabe |
| Extract Inner HTML | Der HTML-Inhalt des ausgewählten Elements. |
| Extract HTML Element | Das ausgewählte Element und dessen HTML-Inhalt. |
| Extract Text | Der Textinhalt des ausgewählten Elements, sowie der Textinhalt aller Unterelemente. |
| Function Value | Das Ergebnis der angegebenen Funktion, z. B. count(//h1), um die Anzahl der h1-Tags auf einer Seite zu ermitteln. |
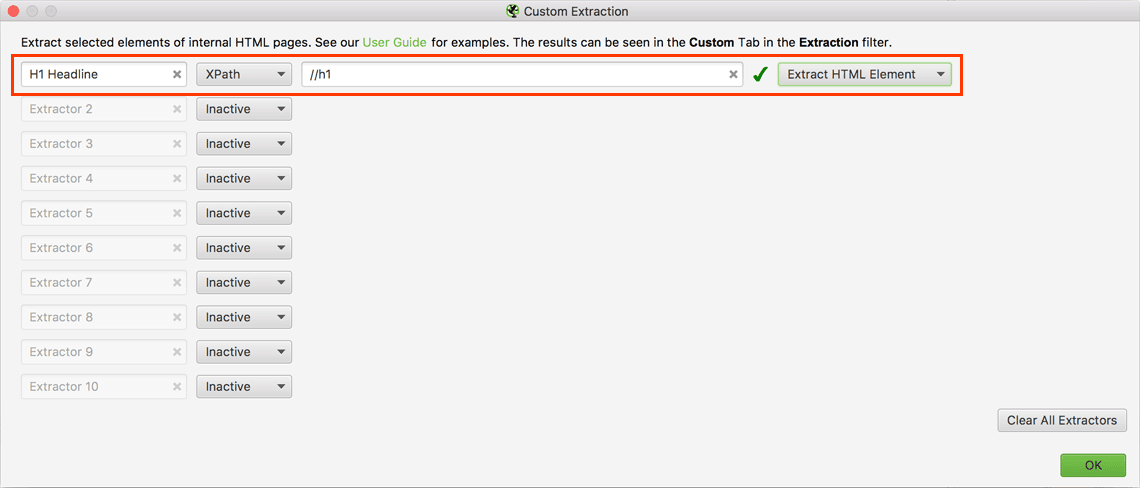
Allgemeine XPath-Beispiele
| XPath Custom Extraction | Beschreibung |
| //h1 | Alle H1 Headlines |
| /descendant::h3[1] | Die erste H3 Headline einer Seite ( [1] beschränkt das Ergebnis auf den ersten gefundenen Treffer) |
| /descendant::h3[position() >= 0 and position() <= 5] | Die ersten fünf H3 Headlines einer Seite |
| //div/span | Alle span-Elemente, die sich in einem div-Container befinden |
| //@href | Alle Links in einem Dokument ( @ bestimmt ein Attribut) |
| //*[@class='underline'] | Alle Elemente mit der Klasse „underline“ ( * bestimmt eine Wildcard) |
| //ul/li[1] | Das erste Listenelement (li) einer ungeordneten Liste (ul) ( [1] beschränkt das Ergebnis auf den ersten gefundenen Treffer) |
| //ul/li[last()] | Das letzte Listenelement (li) einer ungeordneten Liste (ul) |
| //ul[@class='big-list']/li | Alle Listenelemente (li) einer ungeordneten Liste (ul) mit der Klasse „big-list“ |
| //a[contains(@class, 'ajax')] | Alle Links mit der Klasse „ajax“ |
| //a[contains(., 'Weiterlesen')]/@href | Alle Zielseiten mit dem Linktext „Weiterlesen“ |
| //h1[contains(., '2018')] | Alle H1 Headlines die „2018“ enthalten |
| //meta[(@name|@content)] | Meta Tags mit dem Attribut „name“ oder „content“ ( | entspricht dem Operator „oder“) |
| //a[starts-with(@href, 'mailto')] | Alle verlinkten (unverschlüsselten) E-Mail-Adressen |
| //iframe/@src | Alle iFrames-URLs |
| //div[@class="main-section"]//a | Alle Linktexte (Extract Inner HTML) der Links im div-Container mit der Klasse „main-section“ |
| //div[@class="main-section"]//a/@href | Alle URLs (Extract Inner HTML) der Links im div-Container mit der Klasse „main-section“ |
| //div[@class="main-section"]//a | HTML Quellode der Links (Extract HTML Element) im div-Container mit der Klasse „main-section“ |
| //html/@lang | Attribute der Seitensprache ausgeben, zum Beispiel von: <html lang=“de-DE“> |
XPath-Beispiele für SEO-Filter
| XPath Custom Extraction | Beschreibung |
| //div[contains(@class,'main-content')]//a[.='click here'] | Alle Linkelemente mit dem Linktext „click here“ die sich in einem div-Container mit der Klasse „main-content“ befinden |
| //div[contains(@class,'main-content')]//a[@href='url'] | Alle Linkelemente mit einer exakten Ziel-URL die sich in einem div-Container mit der Klasse „main-content“ befinden |
| (//*[@hreflang]) | Alle hreflang-Anmerkungen |
|
(//*[@hreflang])[1] (//*[@hreflang])[2] (//*[@hreflang])[3] |
Die erste hreflang-Anmerkung im HTML Quellcode (Werden mehrere hreflang-Anmerkungen auf einer Seite verwendet, müssen weitere Filter gesetzt werden: … [2]; … [3], usw.) |
| //*[@hreflang]/@hreflang | Alle hreflang-Werte (Sprache-Region) |
| //head/link[@rel='amphtml']/@href | Alle AMP-URLs |
XPath-Beispiele für Strukturdaten-Filter
| XPath Custom Extraction | Beschreibung |
| //meta[starts-with(@property, 'og:title')]/@content | Open Graph Title (Facebook) |
| //meta[starts-with(@property, 'og:description')]/@content | Open Graph Description (Facebook) |
| //meta[starts-with(@property, 'og:image')]/@content | URL des Open Graph Image (Facebook) |
| //meta[@name='twitter:title']/@content | Twittercard Title |
| //meta[@name='twitter:description']/@content | Twittercard Description |
| //meta[@name='twitter:image']/@content | Twittercard Image |
| //*[@itemtype]/@itemtype | Extrahieren aller Arten von Schema-Markups einer Seite |
| //*[@itemprop='streetAddress'] | schema.org Strukturdaten für „streetAdress“ |
| //*[@itemprop='addressLocality'] | schema.org Strukturdaten für „addressLocality“ |
| //*[@itemprop='addressRegion'] | schema.org Strukturdaten für „addressRegion“ |
| //*[@itemprop='name']/@content | Produktname extrahieren |
| //*[@itemprop='description']/@content | Produktbeschreibung extrahieren |
| //*[@itemprop='price']/@content | Produktpreis extrahieren |
XPath testen mit Scraper
Um XPath-Filter zu testen, empfehle ich die Scraper Chrome-Extension aus dem chrome web store. Nach der Installation öffnet man Webseite, dann Rechtsklick und „Scrape Similiar“ wählen. Hier kann man verschiedene Filter testen, bevor man sie im Screaming Frog vor dem Crawl der Website einfügt.
Optional: Beispiele für Regex-Filter
| XPath Custom Extraction | Beschreibung |
| ["'](UA-.*?)["'] | Google Analytics ID der URL extrahieren |
| ["'](GTM-.*?)["'] | Google Tag Manager ID der URL extrahieren |





Danke für die gute Übersicht! Sind gerade dabei, URLs auf Basis von Artikelnummern mit dem Screaming-Frog zu filtern. Funktioniert damit sehr gut! 🙂
Hi,
danke für den hilfreichen Beitrag. Ich komme grad nicht weiter.
Wie müsste eine xpath aussehen, die Links mit einem bestimmten Ankertext nur aus einer Tabelle anzeigt?
//table/a[contains(., ‚Weiterlesen‘)]/@href
Funktioniert leider nicht – wo ist mein Denkfehler?
Danke im Voraus
Hallo Rico,
danke für Deine Nachfrage. Probiere es mal damit:
Beste Grüße
Jens