

Seiteninhalt (Content, Texte, Bilder, Videos, …) zählt für Google zu den wichtigsten SEO-Rankingfaktoren der Websuche. Bei der Berechnung fließen verschiedenste Signale ein. In diesem Blog-Beitrag stelle ich eine beliebte Methode zur Text-Optimierung vor: WDF IDF Analyse. Sie eignet sich deutlich besser als die Optimierung für eine Keyworddichte.

Keyworddichte
Die Keyworddichte (Keyword Density) war in der Suchmaschinenoptimierung lange Zeit hilfreich bei der Text-Optimierung für Google. Heute wird diese Kennzahl nicht mehr verwendet. Googles Rankingfaktoren wurden stetig überarbeitet und verbessert. Die Berechnung einer Keyworddichte ist nicht mehr zeitgemäß. Deshalb empfehle ich für die Optimierung Suchmaschinenrelevanter Texte eine WDF IDF Analyse.
Die Keyworddichte gibt an, wie häufig ein Begriff oder ein Begriffspaar in einem Text vorkommt. Die Formel ist veraltet und wird heute nicht mehr angewendet.
Wie berechnet man die Keyworddichte?
Die Keyworddichte einer Webseite kann durch folgende Formel erfolgen:
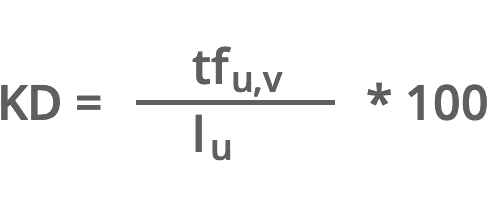
KD = Keyworddichte (Suchwortdichte)
tf = Termfrequenz (Wie oft kommt der Term „u“ in einem Artikel „v“ vor?)
l = Termzahl (Wie viele Terme kommen in einem Artikel „u“ vor?)
Wo liegen die Grenzen der Keyworddichte?
Die Keyworddichte bewertet nur, wie häufig ein Begriff in einem Text vorkommt. Dabei beachtet der Autor i.d.R. keine Synonyme und andere themenrelevante Begriffe. Der Fokus liegt nur auf dem zu optimierenden Keyword. Doch bei der Text-Erstellung gibt es keine zentrale Kennzahl, deren Optimierung ein Top-3 Ranking für das Keyword in der Websuche garantiert. Google’s Algorithmen sind sehr komplex. Texte bewerten sie aus verschiedenen Perspektiven:
- Einzigartigkeit des Inhalts
- Umfang und Vollständigkeit
- Wahrheitsgehalt
- Aktualität des Inhalts (News)
- Lesbarkeit und Textschwierigkeit
- Expertise des Autors zum Thema
- uvm.
Auch wenn der Suchalgorithmus unbekannt ist, gibt Google viele Hilfestellungen für Autoren. Die 23 Panda-Fragen zur Bewertung von Content-Qualität sind zum Beispiel hilfreich.
Die grundlegende Zielstellung ist die Veröffentlichung hilfreicher, einzigartiger Inhalte. Ratsam ist auch der Aufbau eines Expertenstatus und einer hohen Vertrauenswürdigkeit – für manche Branchen sogar erforderlich (YMYL Pages). Wissenswert ist auch der EAT Score.
WDF IDF Analyse
WDF – Within Document Frequency
Die WDF – Within Document Frequency dient zur Berechnung der Gewichtung eines Wortes in einem Dokument.
Ursprung hat die WDF in der Informationswissenschaft. Die Kennzahl dient dazu, die bestmöglichen Treffer zu einem Keyword zu finden. Nicht nur die Keyworddichte, sondern auch der Kontext spielt eine Rolle. Je höher der WDF-Wert, desto häufiger kommt ein Begriff (Term) in einem Dokument vor. Da Suchmaschinen diese und ähnliche Gewichtungsmethoden verwenden könnten, wird WDF IDF als eine Methode (von vielen) zur Text-Optimierung in der SEO angewendet.
WDF Formel
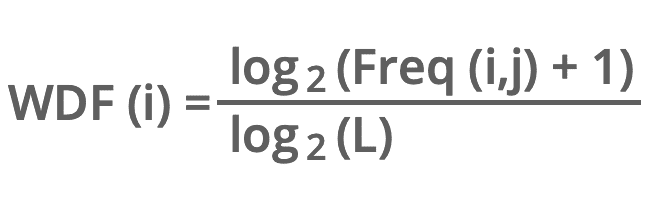
i = Begriff (Term)
j = Dokument
L = Gesamtzahl der Wörter im Dokument „j“
Freq(i,j) = Häufigkeit des Wortes „i“ im Dokument „j“
IDF – Inverse Document Frequency
Die IDF – Inverse Document Frequency ist eine Methode aus der Informationswissenschaft, um die Worthäufigkeit in einem System zu ermitteln.
Optimiert man einen Text für ein spezifisches Keyword, berechnet man mit der WDF-Formel, wie häufig das Keyword vorkommt – bezogen auf alle Wörter im Text. Mit der IDF-Formel errechnet man, wie relevant der Text im Verhältnis zu allen Texten in einem System ist. Wesentlich sind nur Texte, die das gesuchte Keyword enthalten.
IDF Formel
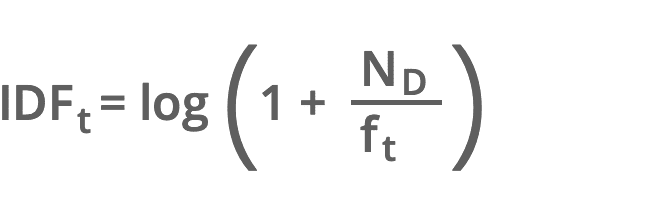
ND = Anzahl der Dokumente
ft = Anzahl der Dokumente die den Term „t“ enthalten
Durchführung einer WDF IDF Analyse
Um die Texteinzigartigkeit für ein Keyword zu ermitteln, müssen WDF und IDF als sich ergänzende Bestandteile betrachtet werden.
WDF IDF Formel
Die WDF IDF Formel besteht aus der WDF- und IDF-Berechnung. Mittels Kombination beider Formeln wird die Termgewichtung ermittelt – bekannt als WDF IDF Analyse.
Doch kein SEO und kein Autor führt eine WDF IDF Text-Optimierung von Hand durch. Im Internet gibt es viele Dienste, mit denen eine WDF IDF Analyse durchgeführt werden kann, die alle Berechnungen abnimmt. Ich verwende die WDF IDF Text-Optimierung der Xovi Suite, weil Sie eine Vielzahl von Filter-Einstellungen und Exportmöglichkeiten bietet – optimal für die Optimierung Suchmaschinenrelevanter Texte.
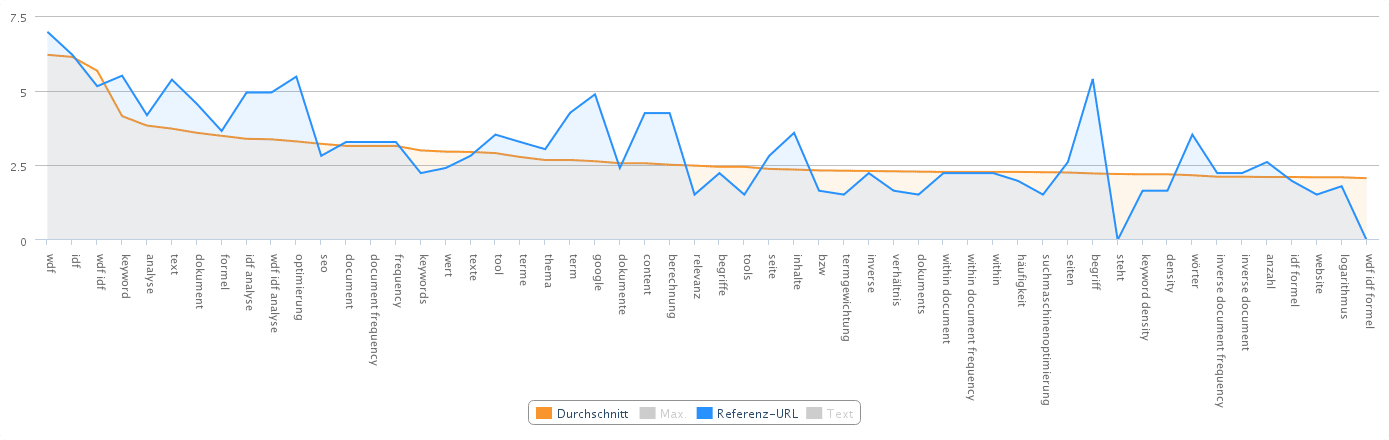
Zunächst gibt man das Keyword, die zu analysierende URL und den gewünschten Suchindex an:
Das Diagramm zeigt nun das Ergebnis der WDF IDF Analyse. Als Benchmark (orangener Graph – Durchschnitt) werden Wörter (Begriffe aus mehreren Wörtern) dargestellt, die häufig vorkommen. (Top-Wettbewerber in Google Websuche für das Keyword) So erfährt man, welche Begriffe nicht oder zu selten im eigenen Text verwendet werden.
Ein Tutorial zur Durchführung einer WDF IDF Analyse mit der Xovi Suite bietet das folgende Video:
Als kostenfreie Software zur WDF IDF Analyse empfehle ich https://www.wdfidf-tool.com/, allerdings bietet es deutlich weniger Filtermöglichkeiten als Xovi oder vergleichbare kostenpflichtige Tools.
WDF IDF ist nur eine von vielen Methoden, um Texte für die Google Websuche zu optimieren. Man darf nicht erwarten, dass eine WDF IDF Text-Optimierung der Schlüssel zu einem Top-10 Google-Ranking ist.
Weiterführende Literatur
- Ryte Wiki: WDF, IDF
- Karl Kratz: SEO Mythos Keyword Density
- Armin Sanjari: Problem der Keyworddichte-Keyworddichte berechnen und analysieren




Hi Jens,
du wie viele andere schreiben ja „Je häufiger ein Begriff (Term) in einem Dokument vorkommt und je seltener dieser in allen Dokumenten des Systems verwendet wird, desto mehr Relevanz baut das Dokument für den Begriff innerhalb des Systems auf“ das ist richtig, aber das galt für Uni Daten bzw für das Militär, etc.
Warum gilt das aber auch für Google?
gehen wir davon aus, dass das auch für Google gilt. Da der IDF für ein Keyword eine Konstante ist (für die verschiedenen zu untersuchenden URLs), dann ist doch der WDF nicht anderes als die Keyworddichte (in gestauchter Form), wie kann da ein Blogger oder Seitenbetreiber feststellen welcher WDF nun gut und welcher schlecht ist?
Lg Armin
Hallo Armin,
du hast vollkommen Recht, die IDF findet ursprünglich im Information Retrieval ihre Anwendung.
Deine berechtigte Frage beantworte ich gern mit meiner Herangehensweise: Für mich ist die WDF relevant, die Keyword-Dichte ist für mich keine Kennzahl mehr, an der ich mich orientiere. Denn bei der Berechnung fehlt der Logarithmus welche die von dir genannte Stauchung erzeugt.
Was ein guter oder schlechter WDF eines Artikels ist kann ich dir leider nicht konkret beantworten. Ich finde, sie hängt auch vom internen und externen Wettbewerb ab, also den Authorities in den SERP’s. Will ich mit einem Text gut ranken, dann mache ich mir vorher konkrete Gedanken zu den Keywords, zur Bildsprache, der thematischen Abhandlung und zur internen Verlinkung. Ich skizziere den semantischen Aufbau des Contents. So schreibe ich viel spezifischer und sparsamer, was sich wiederum positiv für eine hohe WDF des Hauptkeywords auswirkt. Anders ausgedrückt: Ich benötige weniger Terme innerhalb meines Dokuments, um mit dem gewünschten Term eine maximale WDF zu erzeugen.
Mit dieser Methode erziele ich gute Ergebnisse. Natürlich wäre es besser, die WDF der Top Wettbewerber Seiten auszuwerten, aber hier kommen auch weitere Kriterien, wie z. B. die Schlüsselwortabstand der Terme ins Spiel. Du weißt was ich meine.
VG
Das ist schon richtig und deine Art und Weise den WDF zu benutzen ist ja auch nicht verkehrt, jedoch (und das ist ganz wichtig) ist der WDF ohne dem IDF und vorallem ohne dem P genuase relevant wie die Keyworddichte.
Es ist richtig das die Steigung des WDF durch den Log (binären Log) stetig, jedoch nicht so steil ist, jedoch zeigt er bei einer Wettbewerbsanalyse doch nur an wie relevant das Keyword bei anderen URLs ist. Die gleiche Analyse könnte man mit der Keyworddichte durchführen.
Versteh mich nicht falsch, ich halte die Keyworddichte alleine betrachtet für keine Aussagekräftige Kennzahl. Nur ist der WDF auch keine geeignete Kennzahl (alleine betrachtet).
Ich kann dir sagen was der optimale Wert der WDF ist. Theorie 1: Es gibt keinen, weil das Clustermodel eine höhere Gewichtung besitzt.
Theorie 2: Der WDF hat natürlich ein Intervall pro Keyword. In diesem Intervall existiert für jedes Keyword genau ein Optimum.
Lg Armin
Mhh klingt logisch und wahnsinnig mathematisch. Aber ich glaube dir folgen zu können.
Aus deiner Argumentation entnehme ich, dass der WDF eine verlässliche Kennzahl in Kombination mit dem IDF und P ist. Klingt auch logisch. Vielleicht hast du einen Ansatz: Wie willst du die IDF aussagekräftig bewerten, wenn ND = Anzahl der Dokumente (also in diesem Fall Googles Datenbank) nicht definierbar ist?
VG Jens
Sorry das ich erst jetzt schreibe. Das ist ja auch ein sehr mathematisches Thema (darüber wurden ja auch schon Diplom-, Masterarbeiten sowie Phd geschrieben. Deshlab kann man das natürlich nicht in einem Tag alles verstehen).
Diese Gewichtung ist eine gute Kennzahl.
Zum IDF, da habe ich zwar schon ein Tool. Aber ich möchte noch ein paar Tests machen (möchte keine falschen Tipps geben).
Aber für N(D) brauchst du ja nicht alle TxT-Dokus. Ab Platz x sind die Ergebnisse nicht relevant. Du musst bei N(D) mit Mengenoperatoren arbeiten und pro Keyword noch ein wenig ausfiltern.
Lg und schönes WE 🙂
Hey Armin,
wusste gar nicht das du an einem Tool bastelst. 🙂
Halte mich doch mal auf dem Laufenden. Daran bin ich durchaus interessiert.
VG Jens
Hi Jens,
das wird mein zweites Tool. Ich meld mich wenn das Ding on geht. 🙂