

Sind Inhalte im Web durch mehrere URLs aufrufbar, kann Duplicate Content entstehen. Dadurch könnten Suchmaschinen die URL-Version indexieren, die der Webmaster nicht bevorzugt. Durch Canonical Tags kann man das vermeiden. Duplicate Content entsteht auch, wenn Seiten und PDF-Dateien die selben Inhalte besitzen und indexiert werden.
Für Webseiten werden Canonical Tags am einfachsten im Head-Bereich vom HTML Code festgelegt. Sie verweisen auf die bevorzugte Adresse. Canonical Tags können auch für PDF Dateien festgelegt werden. Man benötigt dafür ein wenig technisches Verständnis oder diese Anleitung für Apache Server oder Nginx Server.
Warum können PDF-Dateien Probleme machen?
Besitzt eine PDF-Datei den selben bzw. identischen Inhalt, wie eine Webseite oder eine andere PDF-Datei kann Duplicate Content entstehen. Welche Version die Suchmaschine in den Ergebnissen bevorzugt, kann die Suchmaschine entscheiden. Das ist nicht immer die bevorzugte Version vom Webmaster. Also sollten Canonical Tags festlegen, welche Version des selben Inhalts von Suchmaschinen bevorzugt werden soll. In der SEO wird die bevorzugte Version als kanonisch (canonical) bezeichnet.
Das folgende Beispiel beschreibt eine Keyword-Kannibalisierung von drei URLs (rot, blau, grün) mit dem selben Seiteninhalt, darunter eine PDF-Datei. Die URL-Wechsel sind im Diagramm farblich eingekreist. So wird ersichtlich, dass drei URLs für das selbe Keyword temporär konkurrieren und die Platzierung spürbar einbricht.
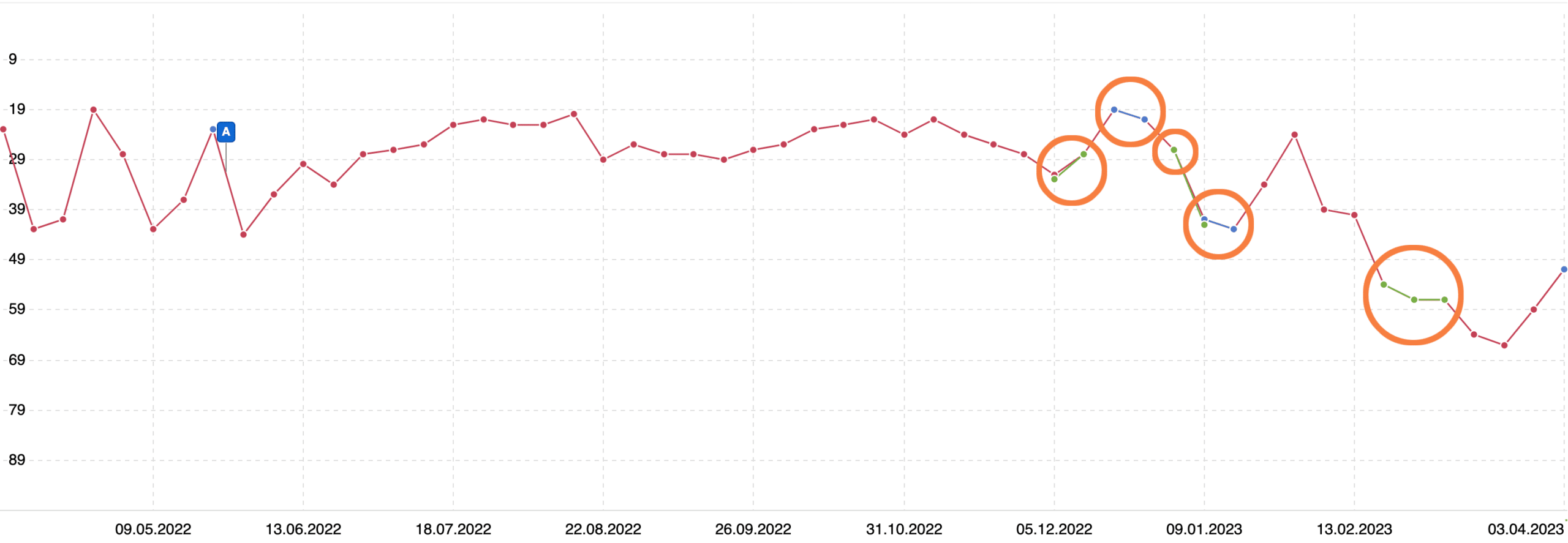
Kanonische URL festlegen
Die Optimierung der Indexierungslogik zählt in das Fachgebiet Technisches SEO. In den meisten Fällen bevorzugt man die Webseite, weil PDF-Dateien einen Bruch zur Website darstellen. In der PDF-Datei fehlen Links zur Website, so dass der Besucher einer PDF-Datei von der Website isoliert ist.
Apache Server: Canonical Tag in htaccess Datei festlegen
In diesem Beispiel erhält die PDF-Datei ein Canonical Tag, das die Webseite mit dem selben Seiteninhalt bevorzugt. Die Webseite darf durch keine Anweisung der robots.txt von der Verarbeitung ausgeschlossen werden und muss indexierbar sein (Meta Robots Tag).
Zur Konfiguration wird das Apache-Modul mod_headers verwendet und folgende Regel in der .htaccess-Datei auf dem Webserver notiert:
|
1 2 3 4 5 |
<IfModule mod_expires.c> <Files test.pdf> Header append Link "<https://example.com/test.html>; rel=\"canonical\"" </Files> </IfModule> |
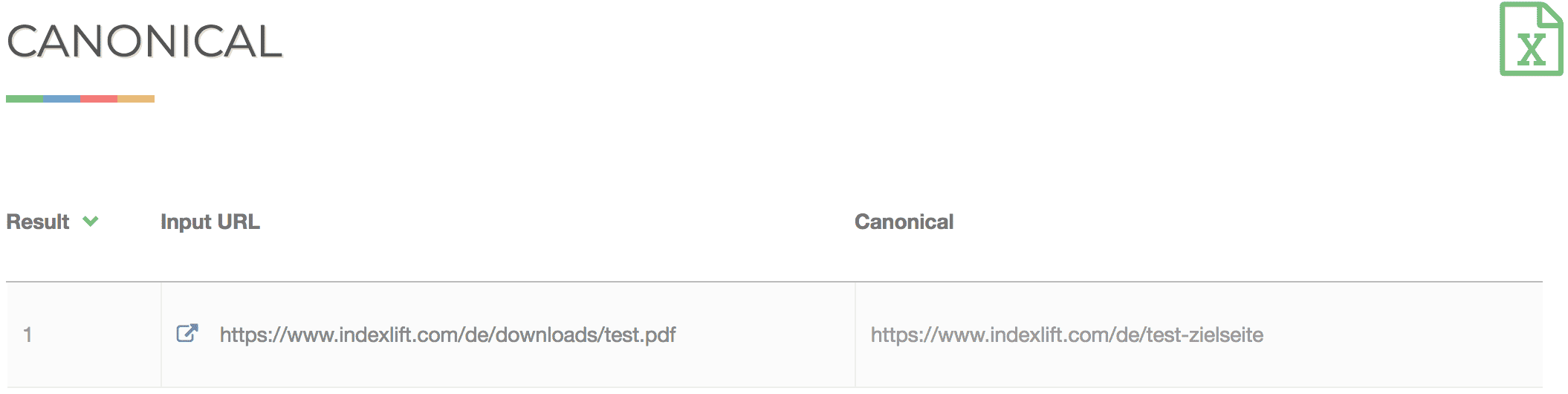
Der Crawler wird angewiesen, die Webseite test.html gegenüber der PDF-Datei test.pdf zu bevorzugen. Dadurch kann Duplicate Content vermieden werden.
- test.pdf muss durch den Dateinamen Deiner PDF-Datei ersetzt werden. Es wird kein absoluter/relativer Pfad notiert.
- https://example.com/test.html wird durch die absolute URL Deiner Webseite ersetzt, die Google bevorzugen soll.
- Für jede PDF-Datei muss eine eigenständige Regel innerhalb des mod_headers erstellt werden.
Nginx Server: Canonical Tag im NGINX Header festlegen
Der Code für das Canonical Tag der PDF-Datei unter https://example.com/test.pdf zur kanonischen Webseite unter https://example.com/test.html sieht wie folgt aus:
|
1 2 3 |
location ~*/test\.pdf$ { add_header Link "<$scheme://$http_host/test.html>; rel="canonical""; } |
Wenn Du diesen Code im HTTP-Header des jeweiligen PDFs auf dem Nginx-Server implementierst, werden dort folgende Informationen an Google gesendet:
|
1 |
Link: <https://example.com/test.html>; rel="canonical" |
Canonical Tag Checker
Das erstellte Canonical Tag sollte anschließend geprüft werden. Zum Beispiel mit dem Canonical Tag URL Location Checker.




Danke für den Tipp!
Wird denn kein Pfad mitgegeben, also wo das test.pdf liegt?
Hallo Chris, das ist nicht erforderlich, probiere es aus.
Beste Grüße
Jens
Hallo Jens,
Sie sind der einzige Lichtblick heute mit meinem PDF-canonical Problem.
Wie sieht der Befehl aus, wenn ich MEHR als eine PDF canonisieren will? Muss dann der komplette Text wiederholt werden (mit den Zeile und
oder nur diese Info:
Header append Link „; rel=\“canonical\““
Merci!
Ich denke, es kommt an die Menge an. Wenn die Anzahl an Regeln überschaubar ist, dann die Anweisung erneut notieren und anpassen:
Ich wünsche maximale Erfolge.
Hallo Jens,
es klappt ganz vorzüglich, mit den PDFs… Nochmals Danke für Ihre Lösung. Könnte man eigentlich auf diese Weise…. grübel … grübel… auch die canonicals der einzelnen .htm Seiten reinschreiben, anstatt diese im header der Dateien zu erfassen?
hab was vergessen…. kann man auch auf einen Anker canonisieren:
Header append Link „; rel=\“canonical\““
Also es wirft keinen Fehlercode aus, aber ist das sinnvoll?
Google crawlt URLs mit Hashtag bzw. Hashbang aber ignoriert diese Anker. Deshalb rate ich davon ab, Canonical-URLs zu bilden, die ein Hashtag bzw. Hashbang besitzen. Weiterhin viel Erfolg.