Duplicate Content liegt vor, wenn derselbe Inhalt oder identische Inhalte auf mehreren Webseiten erscheint. Um doppelten Inhalt zu vermeiden, ist es wichtig, einzigartigen und qualitativ hochwertigen Content zu erstellen. Durch geeignete technische SEO-Maßnahmen kann Duplicate Content auch vermieden werden.
Inhaltsverzeichnis
Interner Duplicate Content
Interner Duplicate Content, also doppelter Inhalt auf einer Domain, entsteht oft durch technische Fehljustierungen. Zum Beispiel wenn Seiteninhalt:
- über HTTP und HTTPS verfügbar ist.
- über www und non-www verfügbar ist.
- auf mehreren Subdomains (Hosts) verfügbar ist.
- durch Groß- und Kleinbuchstaben in der URL erreichbar ist.
- mit und ohne Dateityp (wie „html“ oder „php“) in der URL erreichbar ist.
- mit und ohne Trailing Slash („/“) am Ende der URL erreichbar ist.
- mit und ohne Session ID in der URL erreichbar ist.
- mit und ohne Get Parameter in der URL erreichbar ist.
- durch unterschiedliche Sortierung der Get Parameter in der URL erreichbar ist.
- zusätzlich durch eine Printversion (PDF) abrufbar ist.
Diese und weitere technischen Fehljustierungen lassen sich meist schnell beheben – durch eine Weiterleitung, ein Canonical Tag oder eine Anweisung in der robots.txt-Datei.
Interner Duplicate Content kann auch entstehen, wenn der Seiteninhalt von mehreren URLs identisch ist. Das folgende Beispiel stellt die Google Positionshistorie eines Keywords im Verlauf von zwei Jahren dar. Die Positionshistorie zeigt, dass mehrere URLs abwechselnd und teilweise gleichzeitig für das selbe Keyword in der Google Websuche ranken.
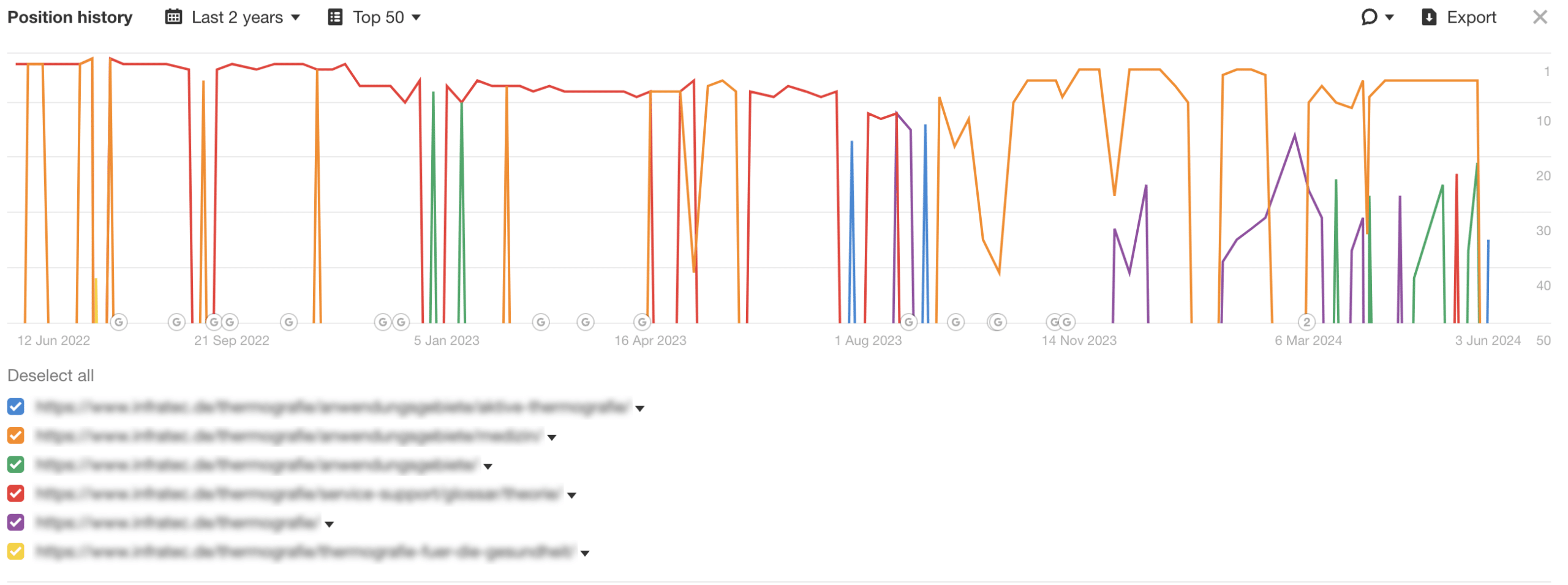
Beispiel für internen Duplicate Content
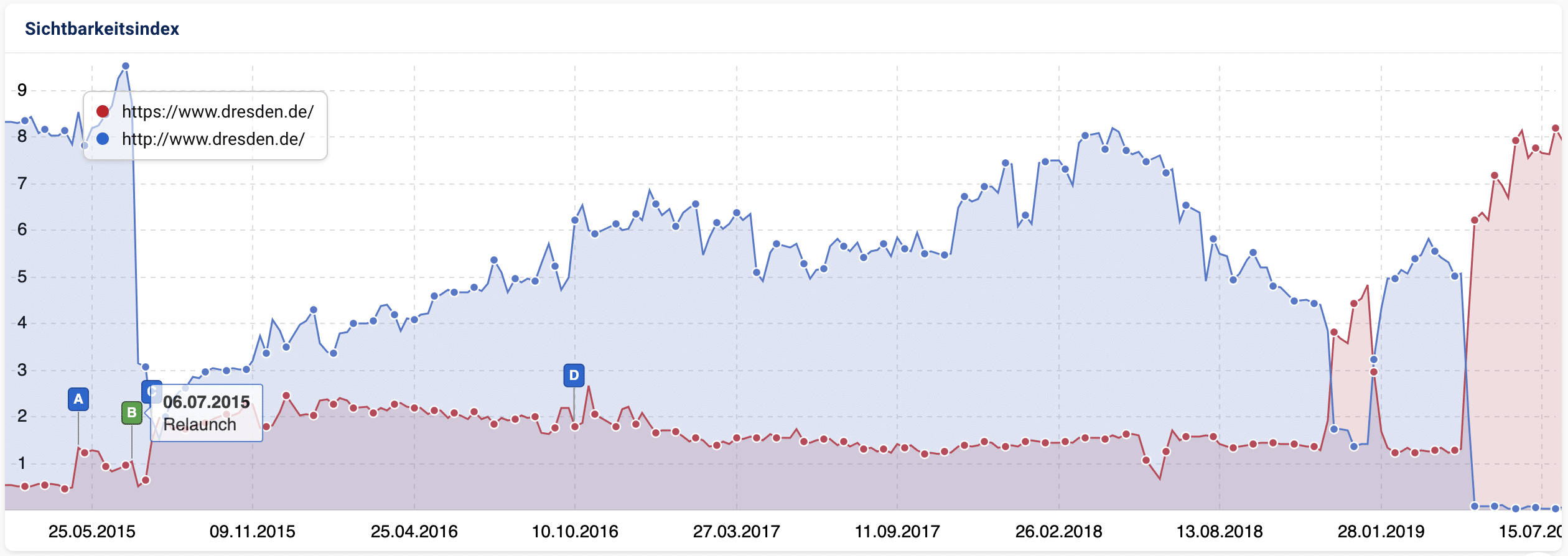
Beispielhaft für internen Duplicate Content ist leider das Stadtportal der Landeshauptstadt Dresden unter dresden.de: Inhalte waren von 2015 bis 2019 durch HTTPS (roter Graph) und HTTP (blauer Graph) erreichbar. Erst durch die Korrektur der technischen Fehlkonfiguration im April 2019 steigt die Google Sichtbarkeit spürbar an.
Externer Duplicate Content
Externer Duplicate Content kann durch unterschiedliche Ursachen erzeugt werden, tritt in der Praxis aber deutlich seltener auf. Meist besitzen mehrere Domains den exakt selben Inhalt (Content Syndication), ohne das eine bevorzugte Domain für Suchmaschinen technisch festgelegt wurde.
Auswirkungen doppelter Inhalte auf die SEO
Keyword-Kannibalisierung
Durch Duplicate Content können wichtige Keyword-Rankings in der Google Suche nicht wie gewünscht aufgebaut werden. Wenn sich Googlebot nicht final auf eine kanonische URL festlegt, konkurrieren mehrere URLs für das selbe Keyword im Wechsel.
Das folgende Diagramm zeigt die Auswirkung von internem Duplicate Content. Zwei Seiten mit identischem Inhalt konkurrieren miteinander für das selbe Keyword. Google weist das Ranking mal URL A (roter Graph) und URL B (blauer Graph) zu. Dadurch werden die Ranking-Potenziale des Keywords nicht ausgeschöpft:
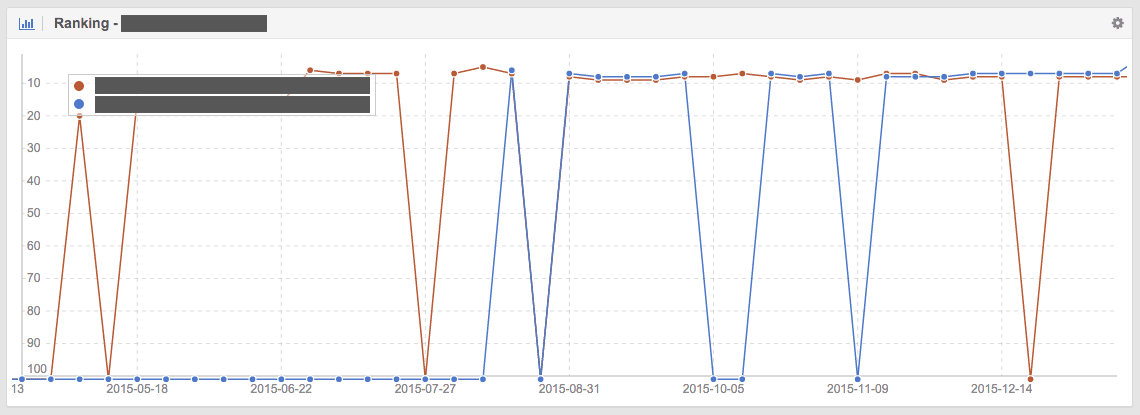
Abstrafung bei unfairen Verhaltensweisen
Es ist durchaus möglich, dass Websites bei offensichtlicher Täuschungsabsicht abgestraft werden können. Zum Beispiel wenn illegale Kopien fremder Inhalte massenhaft publiziert werden. Aufschluss einer möglichen Abstrafung verschafft die regelmäßige Prüfung in der Google Search Console. Google informiert Website-Betreiber bei Vollzug einer Manuellen Maßnahme und benennt die Gründe.
Desktop versus Mobil
Wird eine Website in zwei Varianten bereitgestellt, eine für Desktop-Geräte und eine für mobile Geräte, stellt das keinen Duplicate Content dar. Google nutzt unterschiedliche Crawler zur Indexierung von Inhalten: Googlebot-Desktop und Googlebot-Mobile. Erkennt Googlebot-Mobile die mobile Version einer Website, wird sie für den mobilen Suchindex präferiert und Duplicate Content ist kein Thema. Jedoch muss der Suchmaschine mitgeteilt werden, welche Variante für Mobilgeräte optimiert ist. Bei responsiven Websites ist das Thema obsolet.
Duplicate Content bei großen Websites
Duplicate Content kann bei großen Websites und Shops mit mehreren Millionen URLs zu einem Crawlability-Problem werden. Denn eine Website erhält von Suchmaschinen je nach Relevanz ein gewisses Crawl-Kontingent. Crawlt der User-agent tausende Duplikate, dann besteht die Gefahr, dass wichtige Seiten nicht oder selten verarbeitet werden. Das führt oft zu veralteten Inhalten im Suchindex, besonders bei Produktseiten.
Duplicate Content bei Produktseiten
Ein häufiges Problem von Shops hinsichtlich doppelter Inhalte sind Produktseiten. Viele Hersteller stellen Händlern vorproduzierte Produktinformationen zur Verfügung, oft als Datenfeed. Shop-Betreiber nutzen diese Daten. Das führt zu externem Duplicate Content. Für eine gute Suchmaschinenoptimierung ist es besser für wichtige Produkte unique Produktbeschreibungen zu erstellen, besonders bei erklärungsbedürftigen Produkten.
Minderwertiger Inhalt
Vor wenigen Jahren waren Websites in den Suchergebnissen zu finden, die nichts anderes als gesammelte Informationen von fremden Websites publizierten. Häufig wurden Unmengen von Daten automatisiert gesammelt, logisch zusammengestellt und nach Schema X aufbereitet. Zum Teil waren diese Websites für Nutzer hilfreich. Dennoch strafte Google diese Domains durch eine Manuelle Maßnahme ab. Die Gründe waren minderwertiger Inhalt (Thin Content) und Datenklau. Einzigartige Inhalte mit Mehrwerten für die Besucher sind heute wichtig für gute Google Rankings.
Wie geht Google mit Duplicate Content um?
In dem Video erklärt Matt Cutts von Google, dass etwa 25 bis 30 Prozent aller Inhalte im Web dupliziertem Content entsprechen. Häufig entsteht dieser unbewusst und stellt damit nicht grundsätzlich Spam dar. Dieser lässt sich teilweise auch nicht vermeiden, etwa wenn man Absätze zitiert. Allerdings stellt Google häufig fest, dass viele duplizierte Inhalte keine Mehrwerte für Nutzer bieten. Diese Ressourcen werden von Google ignoriert.
Was versteht Google unter Near Duplicate Content?
Am 11. Juni 2017 erklärte Gary Illyes von Google auf Twitter, dass Near Duplicate Content leicht geänderte Inhalte oder exakt duplizierte Inhalte beschreibt, wobei sich der boilerplate Content unterscheidet. Mit boilerplate sind globale Links in Navigation und Footer gemeint aber auch spezielle Links, zum Beispiel im blogroll (hier mehr) wenn
- jemand einen Teil des Inhalts einer Seite kopiert, diesen leicht ab ändert und auf der eigenen Website veröffentlicht.
- jemand den kompletten Inhalt einer Seite kopiert und ihn auf der eigenen Website veröffentlicht, wobei sich der boilerplate Content unterscheidet.
Was ist kein Duplicate Content?
Mehrsprachige Inhalte einer Website und Zitate (auf eine semantische Auszeichnung achten) sind kein Duplicate Content.
Wie kann man Duplicate Content ermitteln und vermeiden?
Einige Crawl Tools verarbeiten Seiteninhalte und listen Seiten auf, die inhaltlich sehr ähnlich oder exakt gleich sind. Durch dieses Content Audit kann man doppelte Inhalte zielgerichtet beheben.
![]()
Eine zweite Möglichkeit, um Duplicate Content zu ermitteln, ist Copyscape Premium, eine leistungsfähige Plagiatssuche im Internet.
Dritte Option ist die Verwendung von einem Writing Assistent (mein Tipp ist neuronWriter) der bei der Content Erstellung und Optimierung hilft und eine Online-Plagiatsprüfung bietet.